Author: Ann Jackson
-

Installing Tableau Server on Linux – Tableau 2021.1 Edition
It’s been over 2 years since we wrote our original blog post on installing Tableau Server on a Linux machine, to date it remains our most trafficked blog post. Since Tableau has continued to release new versions, we decided it was time to update our blog to reflect a new deployment. Just like before, we’re…
-
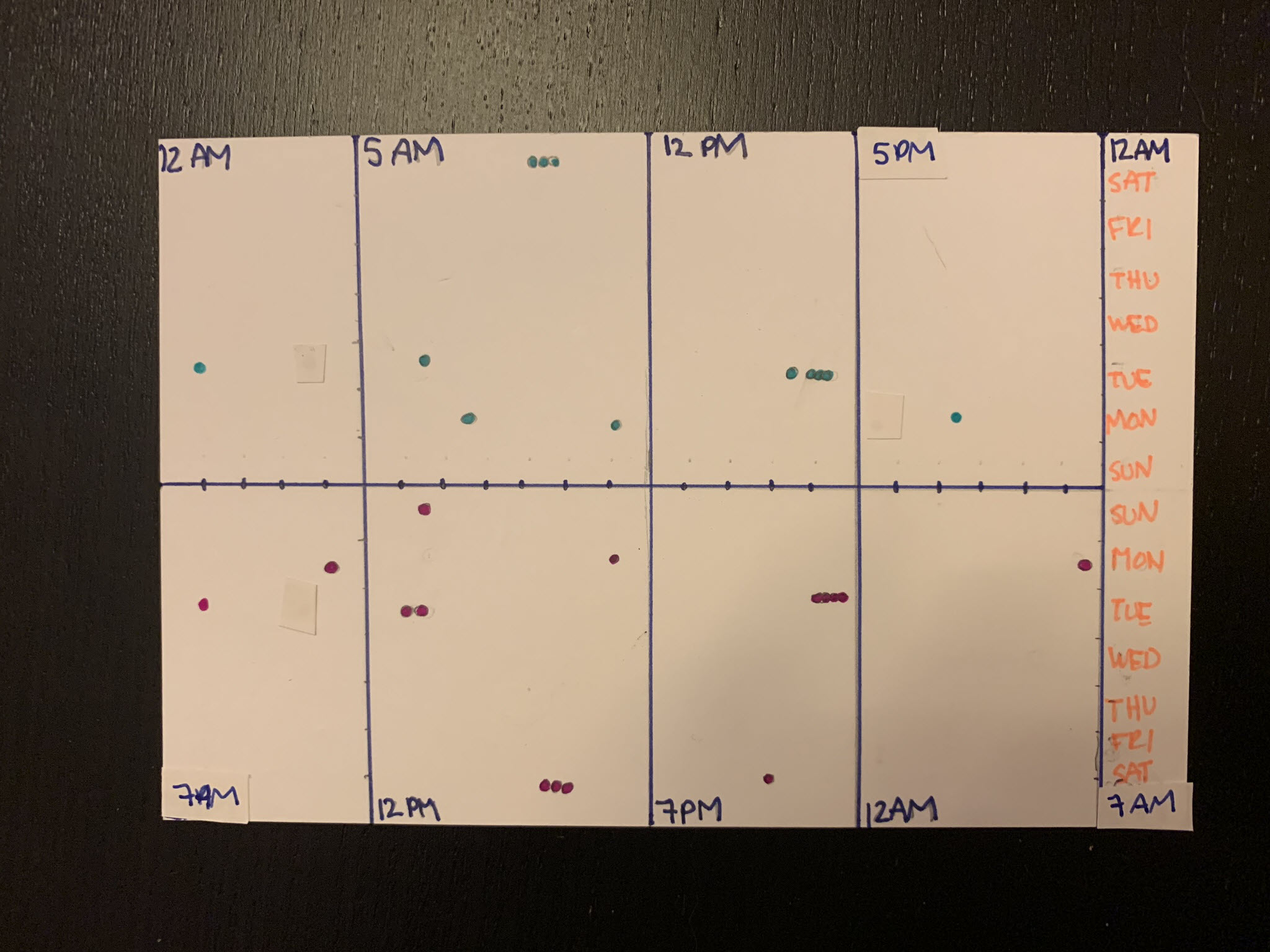
Dear Data 2019 – Week 10, Data Pals
Week 10 postcards are finally here for the data postcard project Sarah Bartlett and I are working on. The topic for the week was our relationship with each other. How much do we communicate, how often, when, and so on. And the timing was fantastic – Sarah and I recorded a video feedback session for…
-

Dear Data 2019 – Week 9, To Do Lists
Week 9 of the data postcard project Sarah Bartlett and I are working on have arrived. The topic of the week was To Do Lists. I don’t actively keep good lists of tasks – they make me sad – especially when I have tasks that continue to go undone. I also think they miss describing/capturing…
-
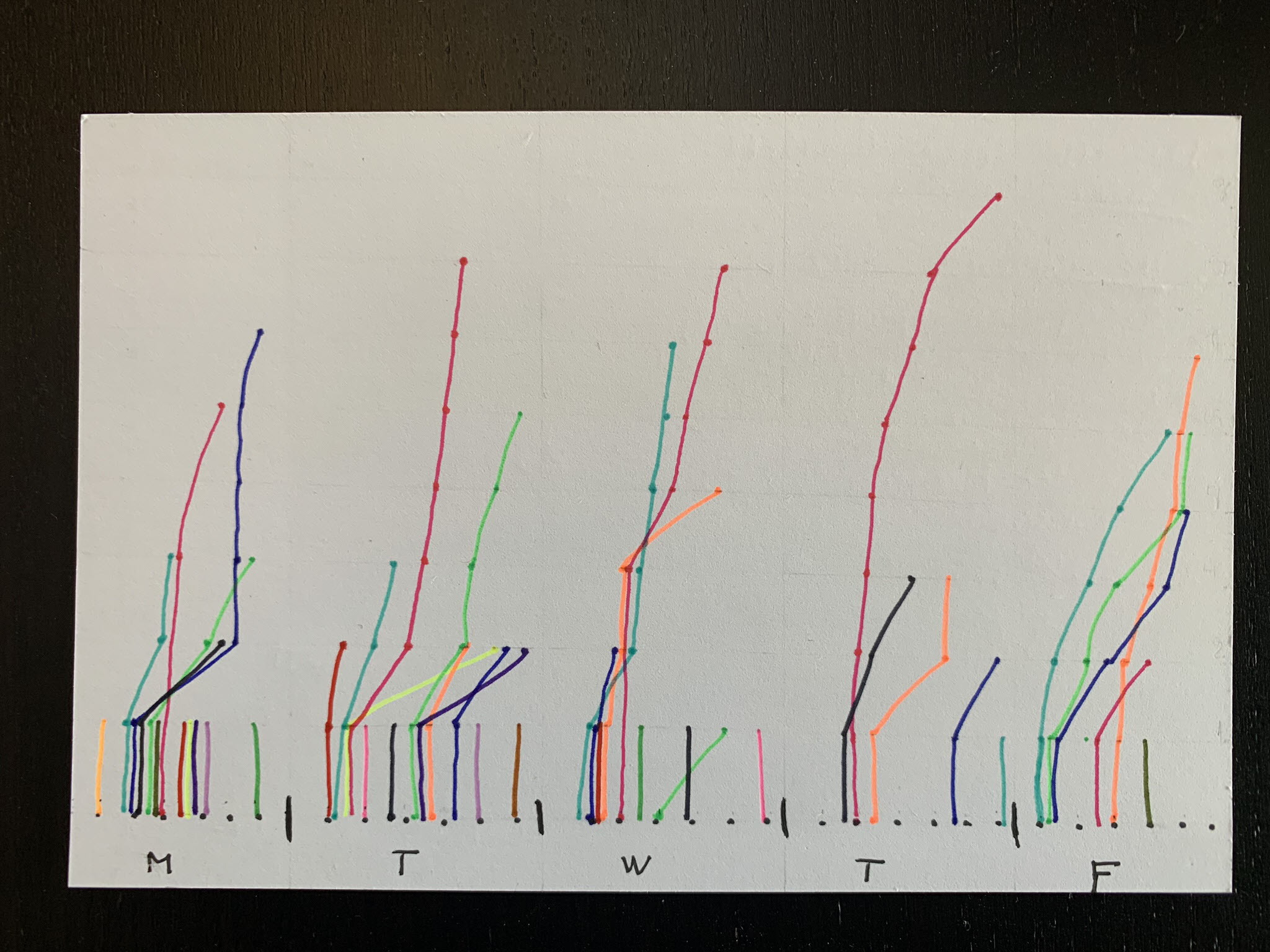
Dear Data 2019 – Week 8, Phone Addiction
After the terrible flurry of complaints, Sarah and I continued on with week 8 of the dear data postcard project we’re conducting. Week 8 was a welcome change, tracking how often we use our phones. I was excited to jump on this topic to know more insight into what I’m doing on my phone (although…
-

Dear Data – Week 7, Complaints
Week 7 postcards have long been delivered and this blog post is overdue. As if the subject for the cards had some influence, the theme of complaints seemed to have an extremely negative impact on having the desire to write the companion blog post. During this week I tried to track all of my verbal…
-
Installing Tableau Server on Linux (Ubuntu LTS 16.04)
Over the past six months we’ve noticed a trend – most of our clients are interested in installing Tableau Server on Linux (opposed to Windows). In fact at the recent Tableau Conference, over 25% of new Server installs were attributed to Linux distributions. With that sense of growing popularity, we wanted to take some time…
-

Dear Data 2019 – Week 6, Physical Contact
Week 6 postcards of the data project Sarah Bartlett and I are working on are here and I couldn’t be more excited. The theme of week 6 was physical contact. During the original project Giorgia and Stefanie tracked people they touched and who touched them, but I decided to switch things up and include my…
-

Dear Data 2019 – Week 5, Purchases
Week 5 of the data postcard project Sarah Bartlett and I are working on has long arrived and this blog post is overdue. I am a tiny bit behind schedule and can’t blame timing on the mail for this week! The topic to track and visualize this week was items we purchased. So for this…
-
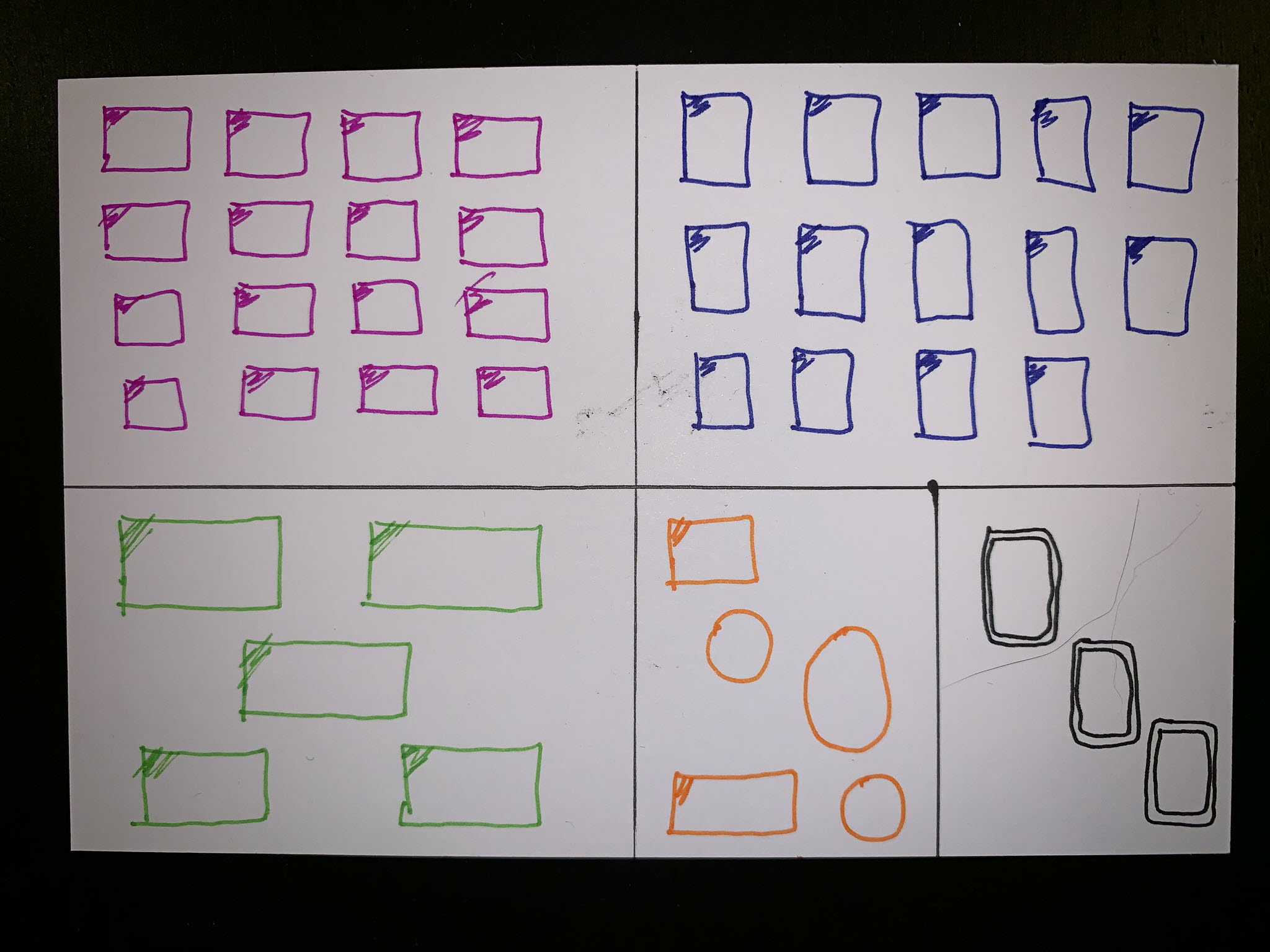
Dear Data 2019 – Week 4, Mirrors
Week 4 of the data postcard project Sarah Bartlett and I are working on this year is here. We still have yet to reach consistent timing for postcard arrival. Sarah usually receives mine 2 days or more before I receive hers, but this week we were only one day apart. Week 4’s topic was all…
-
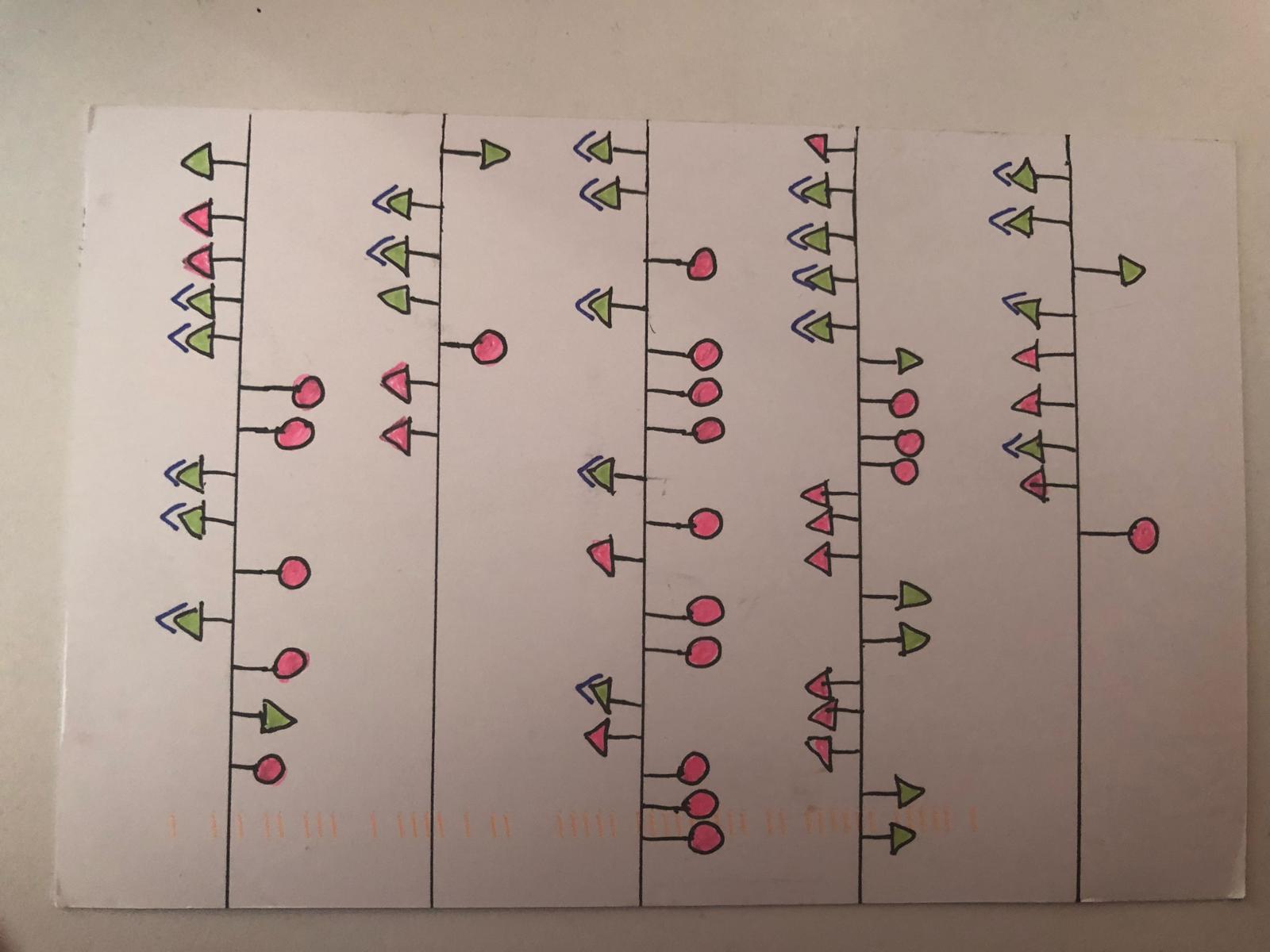
Dear Data 2019 – Week 3, Thank Yous
Week 3 postcards for the data project Sarah Bartlett and I are working on this year have finally reached their destinations. I think we both felt that the mail was slower than normal, perhaps due to the abnormally cold weather here in the US. Week 3’s topic was tracking how often we say “thank you.”…