Dying Out, Bee Colony Loss in US | #MakeoverMonday Week 18
Week 18 of Makeover Monday tackles the issue of the declining bee population in the United States. Data was provided by BeeInformed and the re-visualization is in conjunction with Viz …
Data Visualization & Analytics Consulting

Week 18 of Makeover Monday tackles the issue of the declining bee population in the United States. Data was provided by BeeInformed and the re-visualization is in conjunction with Viz …
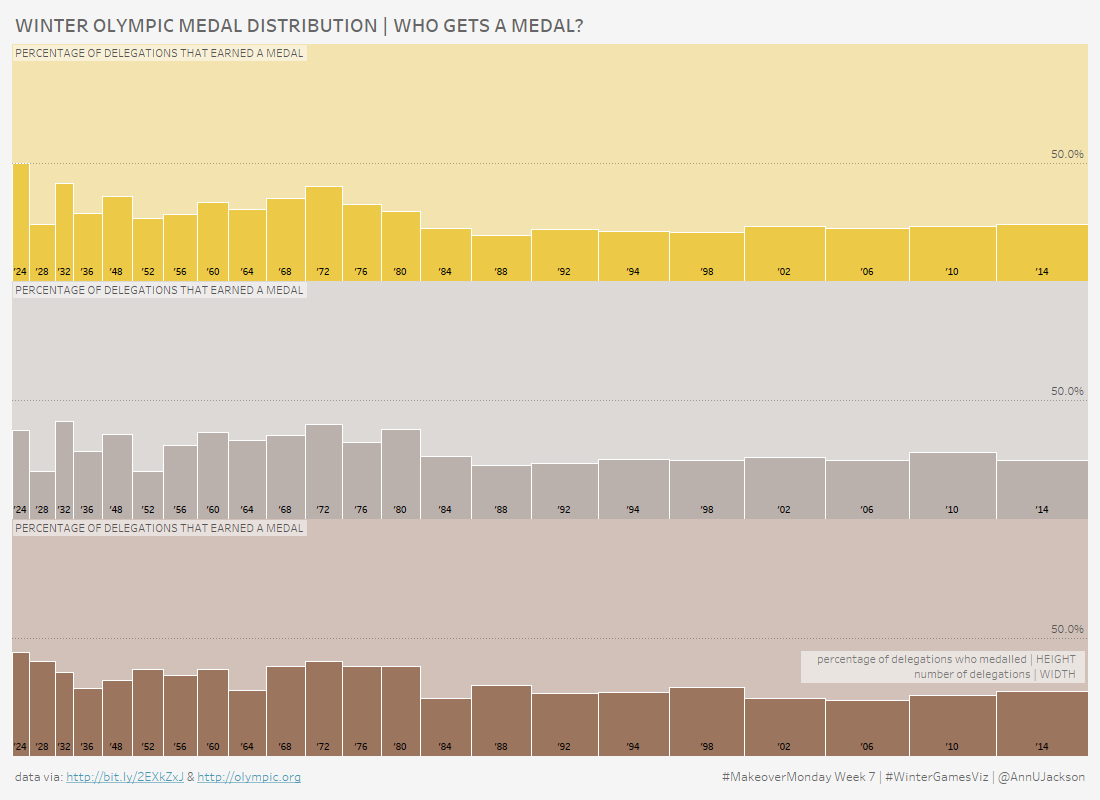
At the time of writing the 2018 Winter Olympic Games are in full force, so it seems only natural that the #MakeoverMonday topic for Week 7 of this year is …
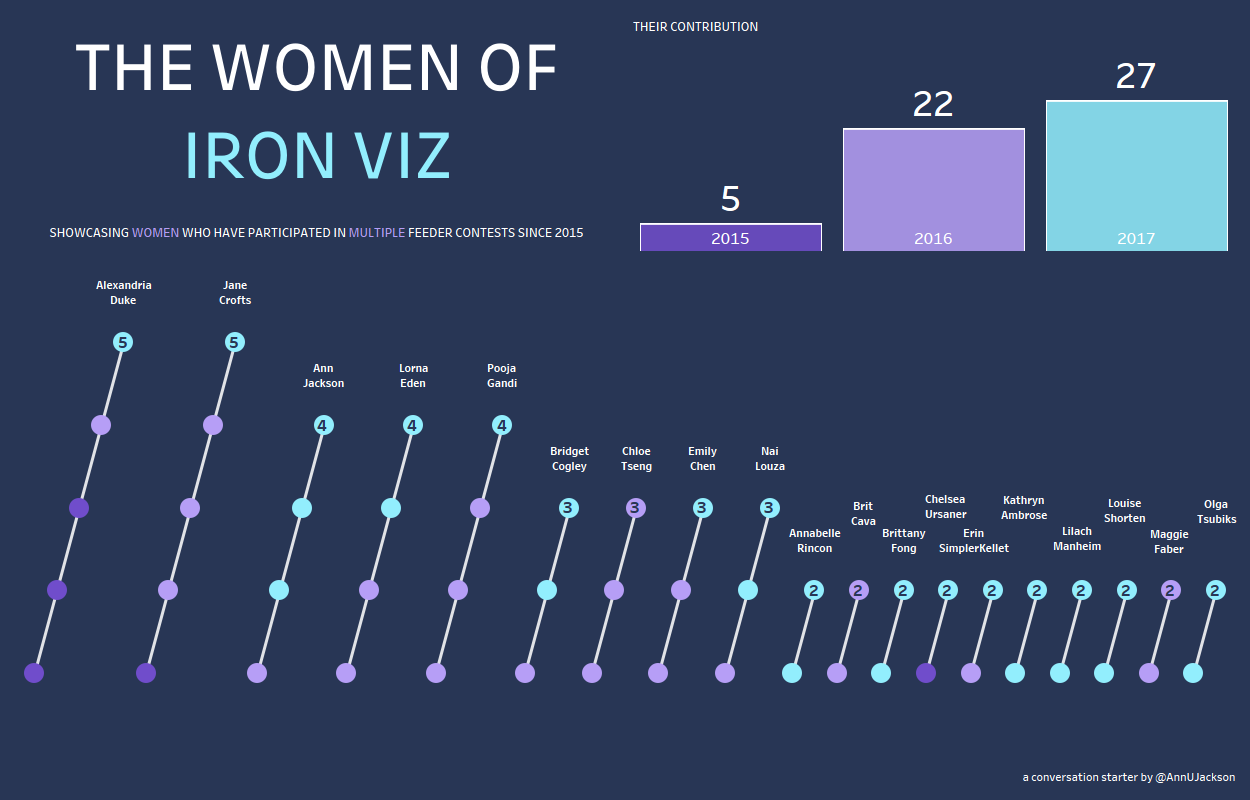
It’s now 5 days removed from the Tableau Conference (#data17) and the topic of women in data visualization and the particularly pointed topic of women competing in Tableau’s #IronViz competition …

Now that Tableau Conference 2017 has come to a close it’s time to reflect back on my favorite and most memorable moments. I’ll preface by saying that I had very …

We had another giant data set this week – 202 million records of EPA Ozone readings across the United States. The giant data set is generously hosted by Exasol. I …
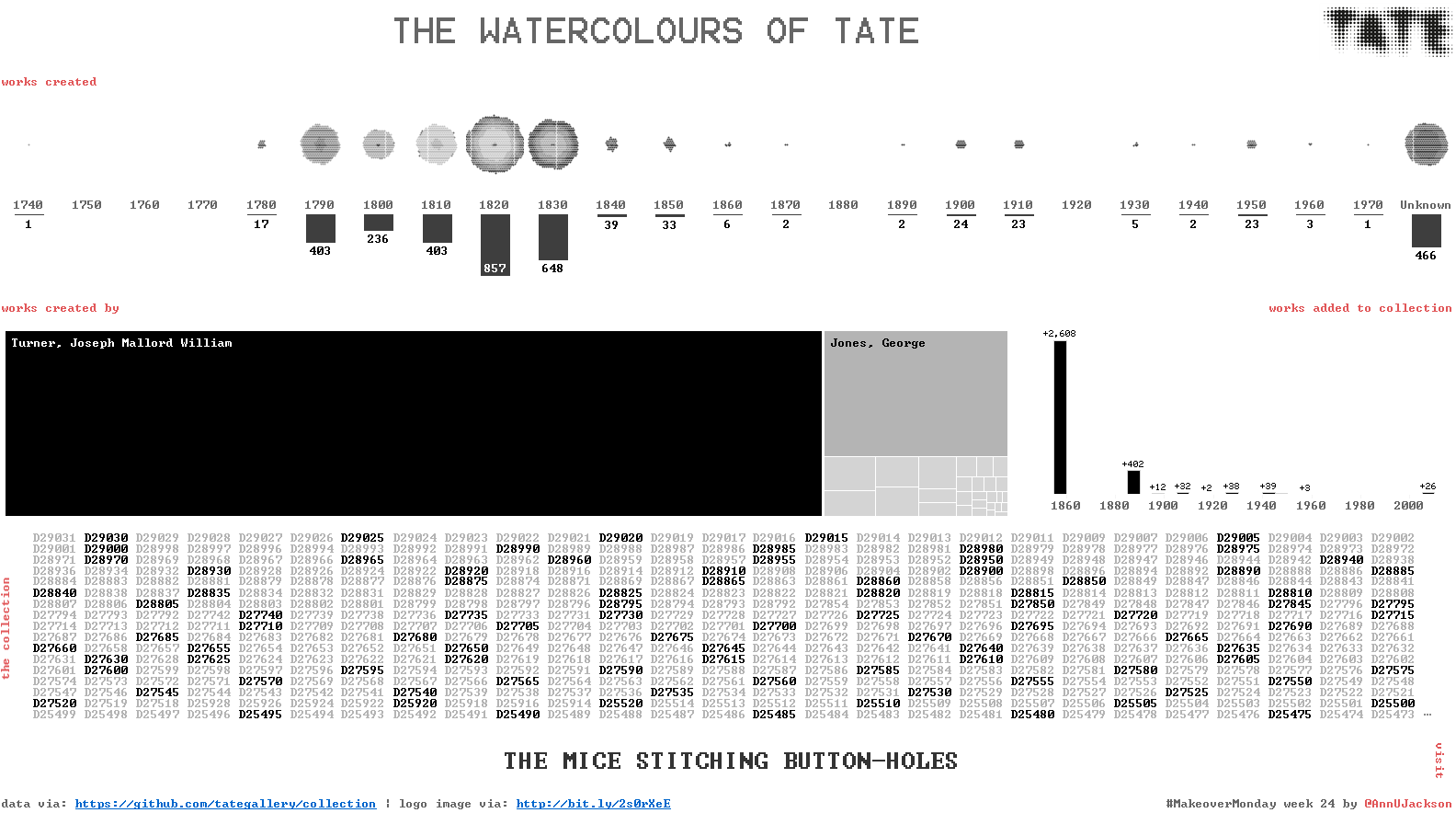
First – I apologize. I did a lot of web editing this week that has led to a series of system fails. The first was spelling the hashtag wrong. Next …
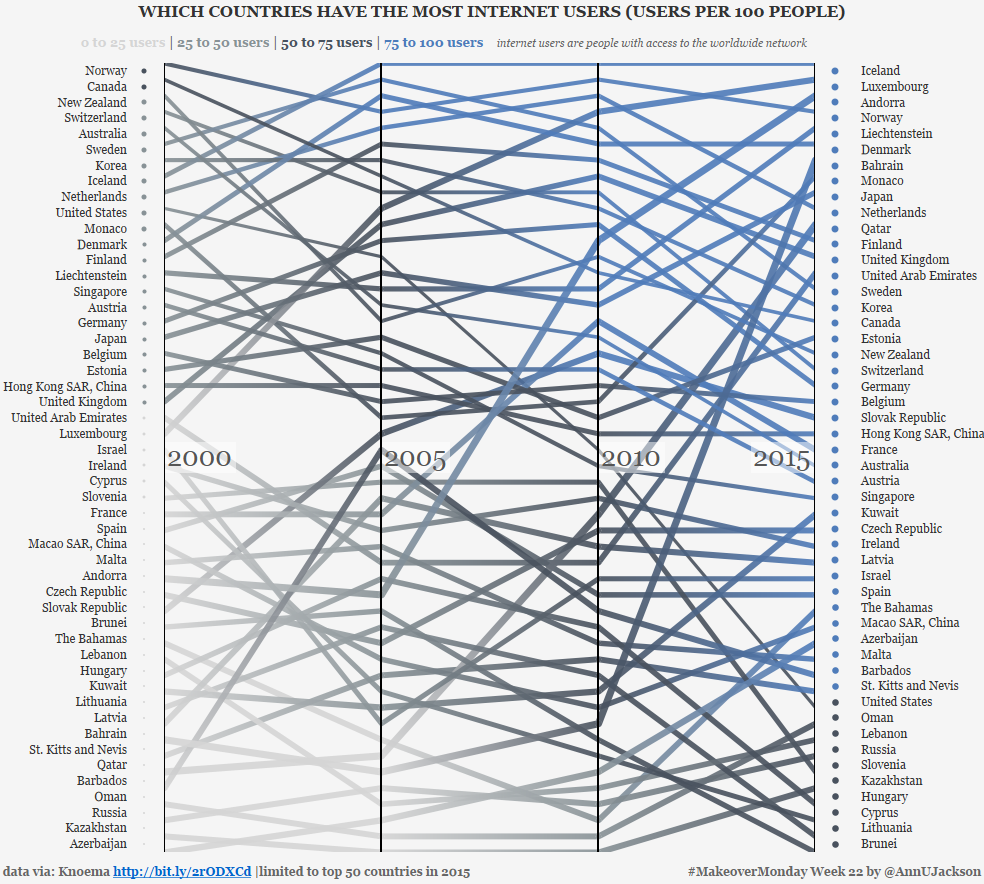
This week’s data set demonstrates the number of users per 100 people by country spanning several years. The original data set and accompanying visualization starts as an interactive map with …

After some botched attempts at reestablishing routine, #MakeoverMonday week 21 got made within the time-boxed week! I have one pending makeover and an in-progress blog post to talk about Viz …
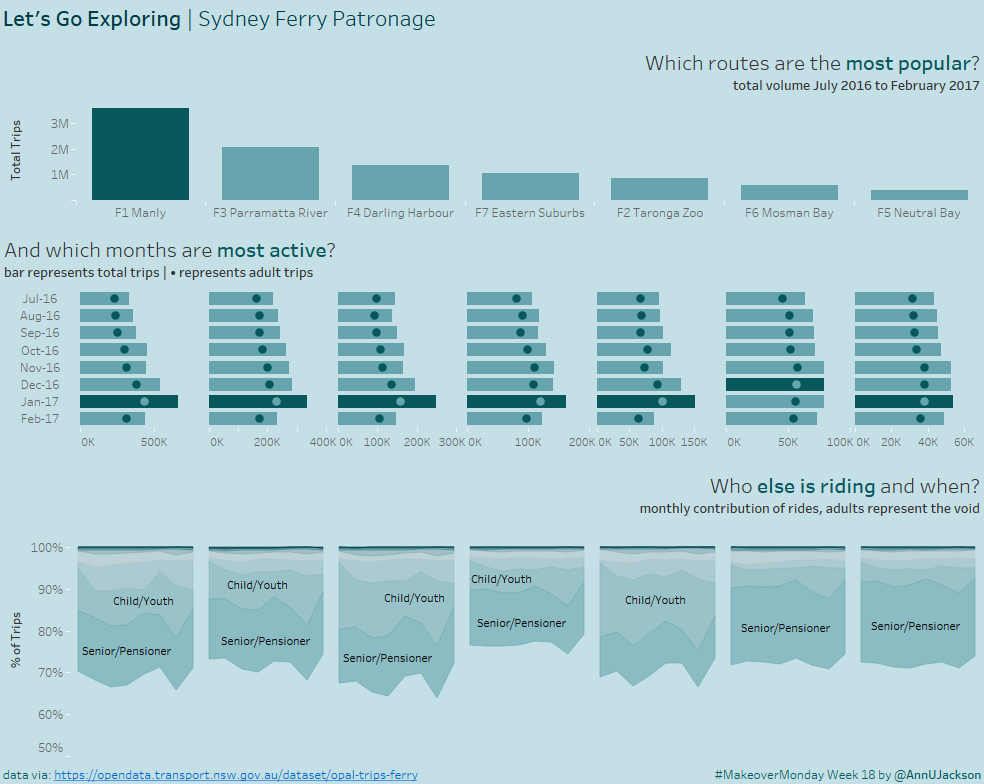
{witty intro} This week’s makeover challenge was to take Sydney ferry data for 7 ferry lines and 8 months. What’s even better is there was another dimension with a domain …

After a bit of life prioritization, I’m back in full force on a mission to contribute to Makeover Monday. To that end, I’m super thrilled to share that I’ve completed …