We’re officially 10 weeks into Makeover Monday, which is a phenomenal achievement. This means that I’ve actively participated in recreating 10 different visualizations with data varying from tourism, to Trump, to this week’s Youtube gamers.
First some commentary people may not like to read: the data set was not that great. There’s one huge reason why it wasn’t great: one of the measures (plus a dimension) was a dependent variable on two independent variables. And that dependent variable was processed via a pre-built algorithm. So it would almost make sense to use the resultant dependent variable to enrich other data.
I’m being very abstract right now – here’s the structure of the data set:

Let’s walk through the fields:
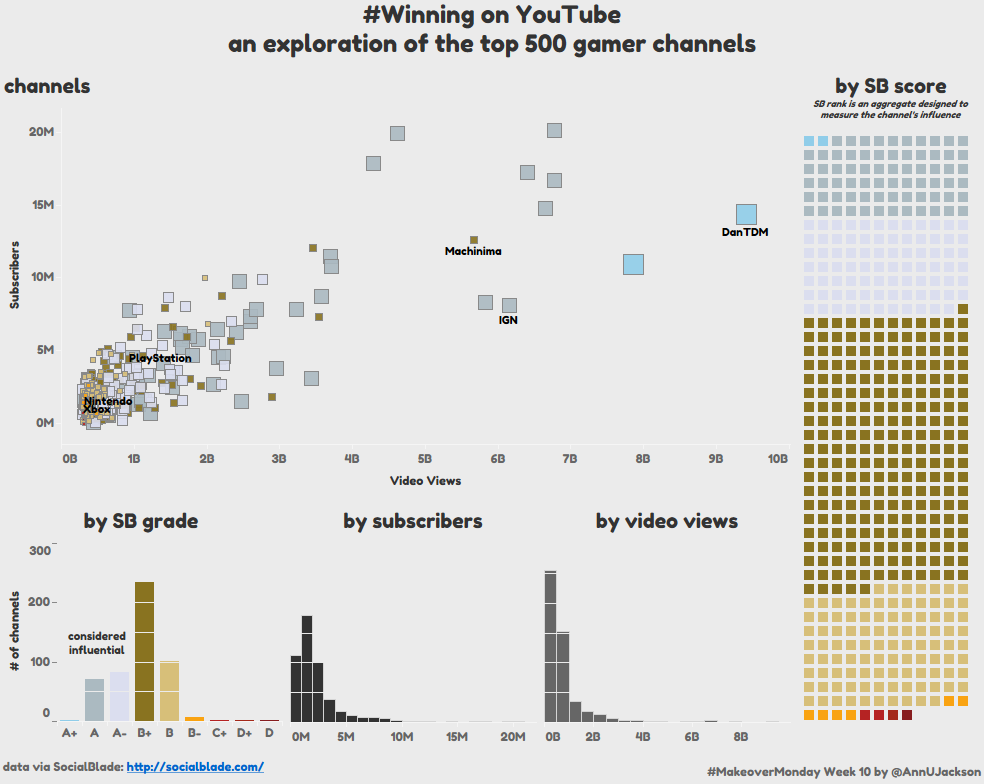
- Rank – this is a component based entirely on the sort chosen by the top (for this view it is by video views, not sure what those random 2 are, I just screencapped the site)
- SB Score/Rank – this is some sort of ranking value applied to a user based on a propriety algorithm that takes a few variables into consideration
- SB Score (as a letter grade) – the letter grade expression of the SB score
- User – the name of the gamer channel
- Subscribers – the # of channel subscribers
- Video Views – the # of video views
As best as I can tell through reading the methodology – SB score/rank (the # and the alpha) are influenced in part from the subscribers and video views. Which means putting these in the same view is really sort of silly. You’re kind of at a disadvantage if you scatterplot subscribers vs. video views because the score is purportedly more accurate in terms of finding overall value/quality.
There’s also not enough information contained within the data set to amass any new insights on who is the best and why. What you can do best with this data set is summarization, categorization, and displaying what I consider data set “vitals.”
So this is the approach that I took. And more to that point, I wanted to make over a very specific chart style that I have seen Alberto Cairo employ a few times throughout my 6 week adventure in his MOOC.
That view: a bar chart sliced through with lines to help understand size of chunks a little bit better. This guy:

So my energy was focused on that – which only happened after I did a few natural (in my mind) steps in summarizing the data, namely histograms:


Notice here that I’ve leveraged the axis values across all 3 charts (starting with SB grade and through to it’s sibling charts to minimize clutter). I think this has decent effect, but I admit that the bars aren’t equal width across each bar chart. That’s not pleasant.
My final two visualizations were to demonstrate magnitude and add more specifics in a visual manner to what was previously a giant text table.
The scatterplot helps to achieve this by displaying the 2 independent variables with the overall “SB grade” encoded on both color and size. Note: for size I did powers of 2: 2^9, 2^8, 2^7…2^1. This was a decent exponential effect to break up the sizing in a consistent manner.
The unit chart on the right is to help demonstrate not only the individual members, but display the elite A+ status and the terrible C+, D+, and D statuses. The color palette used throughout is supposed to highlight these capstones – bright on the edges and random neutrals between.
This is aptly named an exploration because I firmly believe the resultant visualization was built to broadly pluck away at the different channels and get intrigued by the “details.” In a more real world I would be out hunting for additional data to tag this back to – money, endorsements, average video length, number of videos uploaded, subject matter area, type of ads utilized by the user. All of these appended to this basic metric aimed at measuring a user’s “influence” would lead down the path of a true analysis.
Leave a Reply