Exploring Python + Tableau
This month I’ve been taking a night class at Galvanize aimed at being an introductory to Python and Data Science. It’s a 4 night/week boot camp with a mix of …
Data Visualization & Analytics Consulting
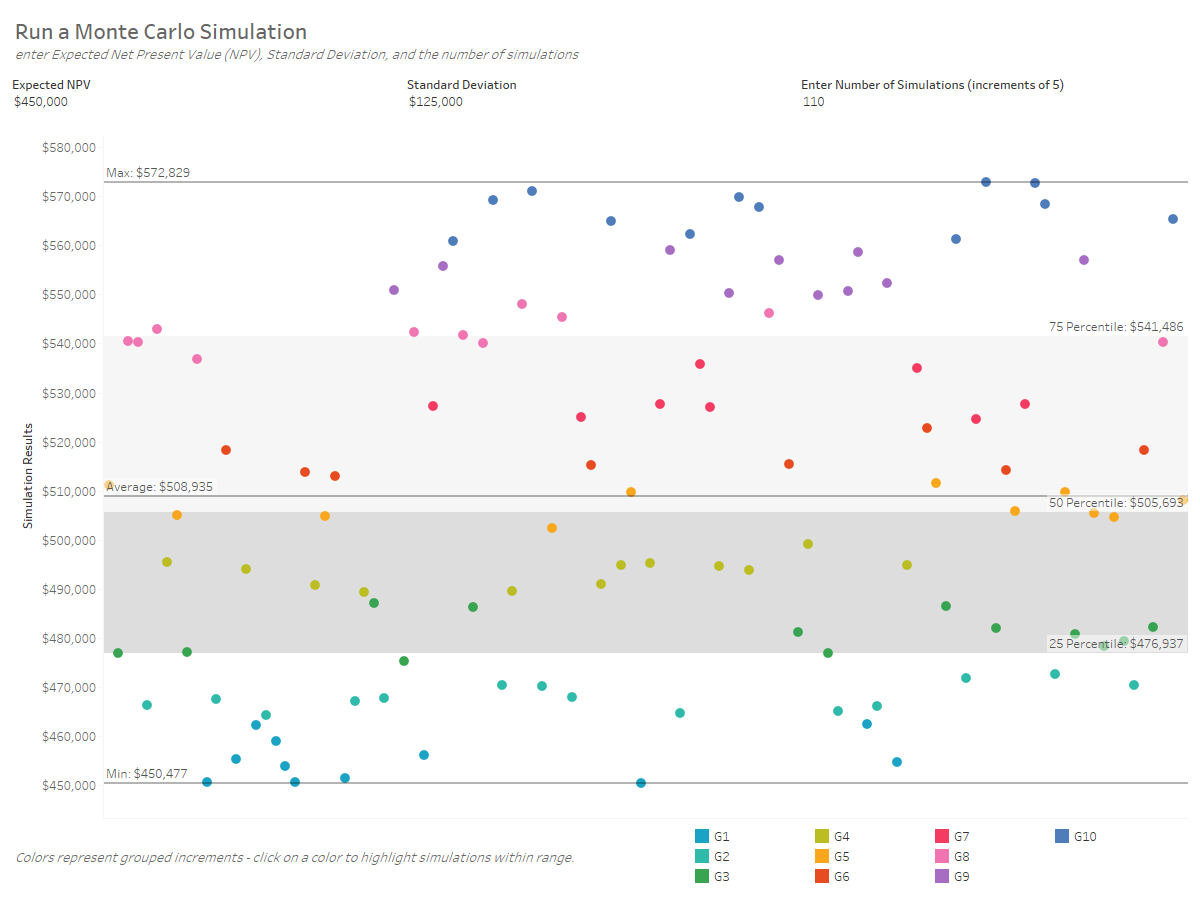
This month I’ve been taking a night class at Galvanize aimed at being an introductory to Python and Data Science. It’s a 4 night/week boot camp with a mix of …