Makeover Monday Week 8 – Potatoes in the EU
I’ll say this first – I don’t eat potatoes. Although potatoes are super tasty, I refuse to have them as part of my diet. So I was less than thrilled …
Data Visualization & Analytics Consulting
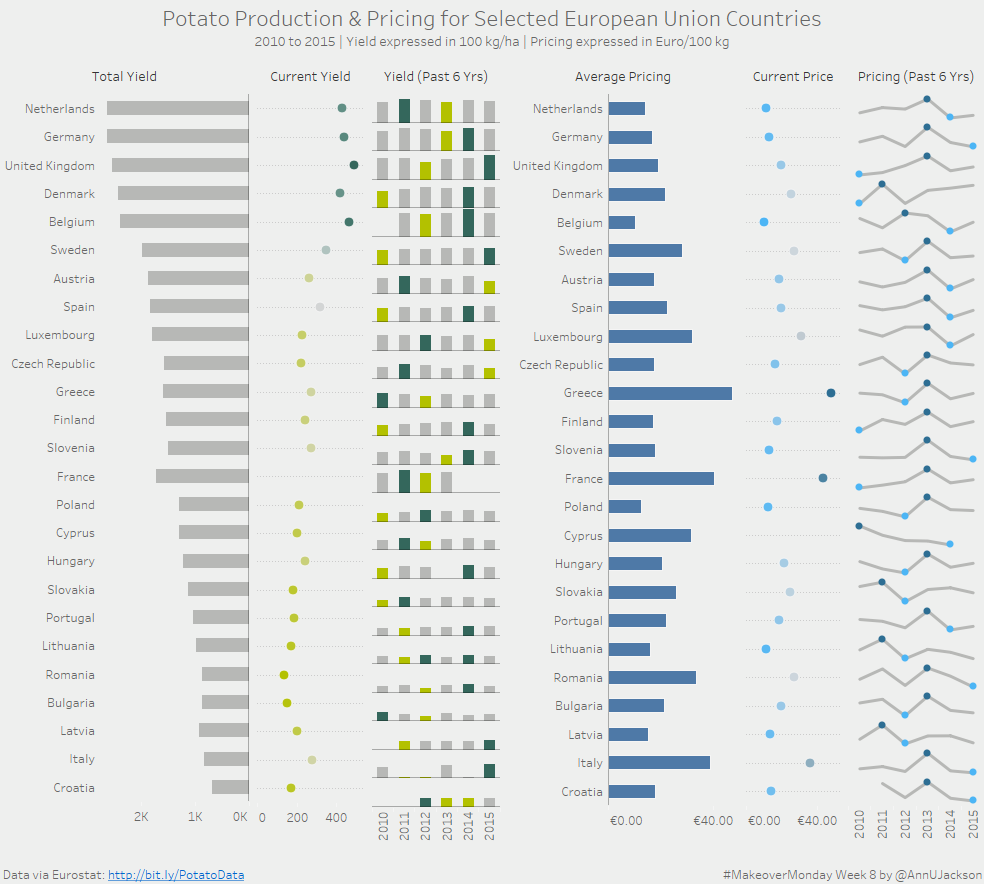
I’ll say this first – I don’t eat potatoes. Although potatoes are super tasty, I refuse to have them as part of my diet. So I was less than thrilled …

This week’s data set presented itself with a new and unique challenge – 100 million plus records and a slight nod to #IronViz 2016. #MakeoverMonday is just around the …

It’s time for another edition of book binge – a random category of blog posts devised (and now only on its second iteration) where I walk through the different books …