Workout Wednesday Week 17: Step, Jump, or Linear?
What better way to celebrate the release of step lines and jump lines in Tableau Desktop with a workout aimed at doing them the hard way? Using alternative line charts …
Data Visualization & Analytics Consulting
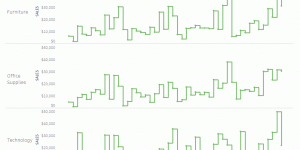
What better way to celebrate the release of step lines and jump lines in Tableau Desktop with a workout aimed at doing them the hard way? Using alternative line charts …
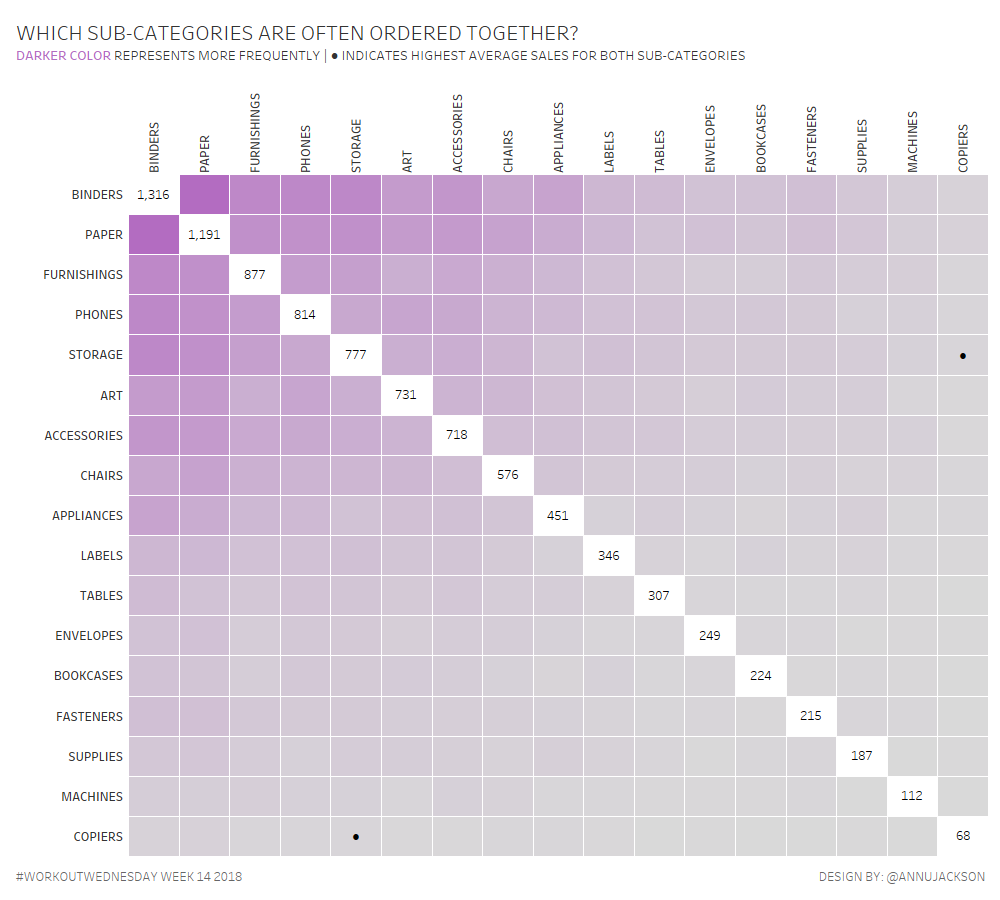
Earlier in the month Luke Stanke asked if I would write a guest post and workout. As someone who completed all 52 workouts in 2017, the answer was obviously YES! …
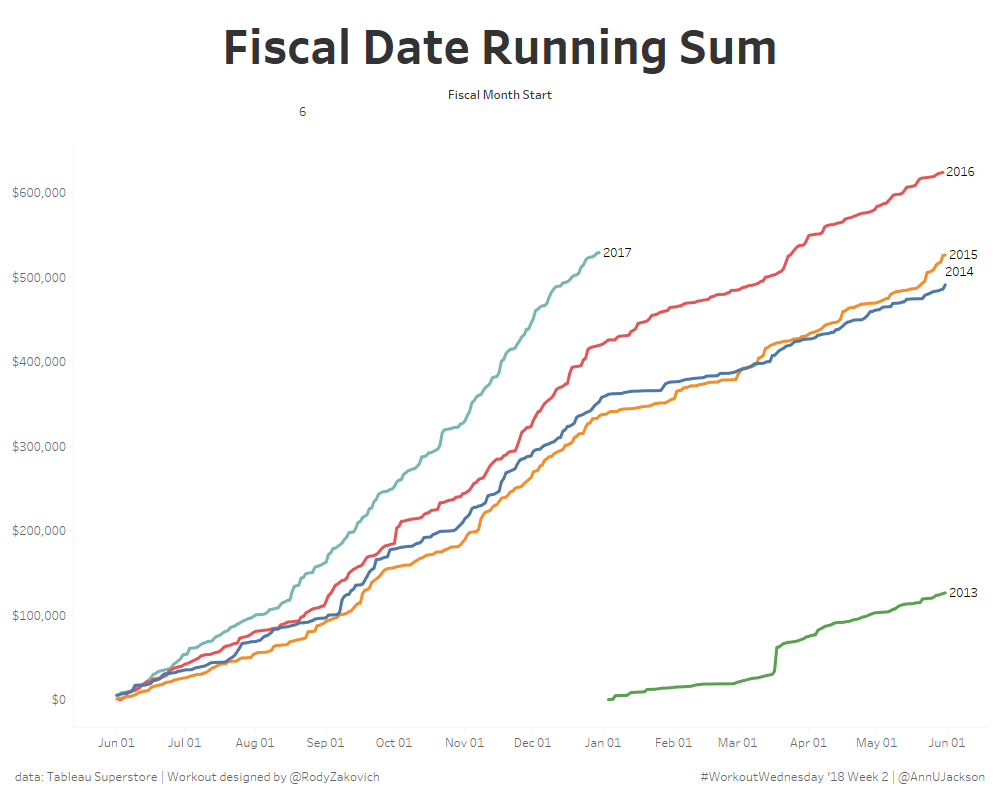
As a big advocate of #WorkoutWednesday I am excited to see that it is continuing on in 2018. I champion the initiative because it offers people a constructive way to …
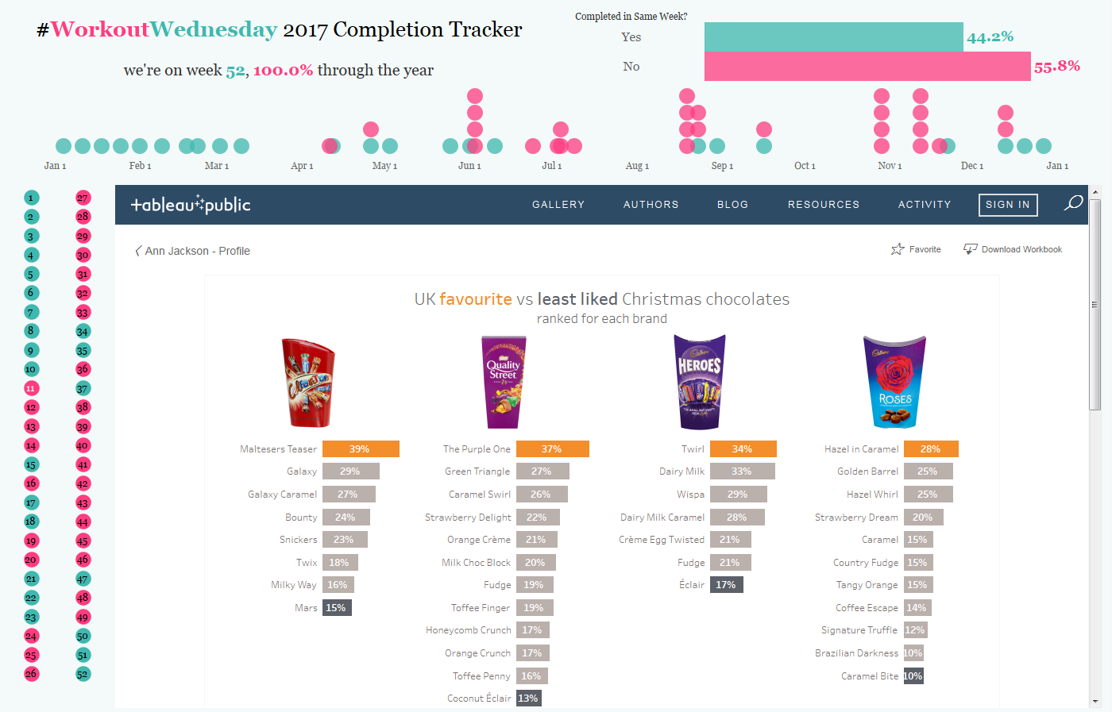
Back in July I wrote the first half of this blog post – it was about the first 27 weeks of #WorkoutWednesday. The important parts to remember (if the read …
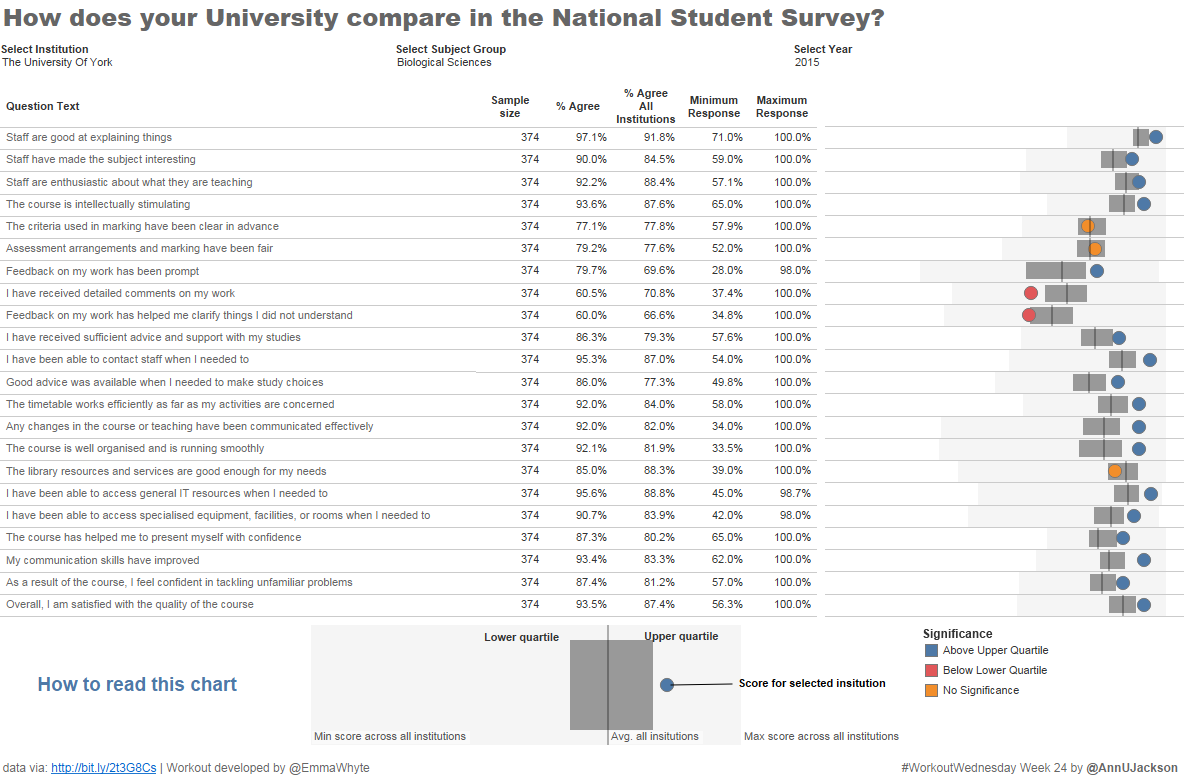
The Workout Wednesday for week 24 is a great way to represent where a result for a particular value falls with respect to a broader collection. I’ve used a spine …
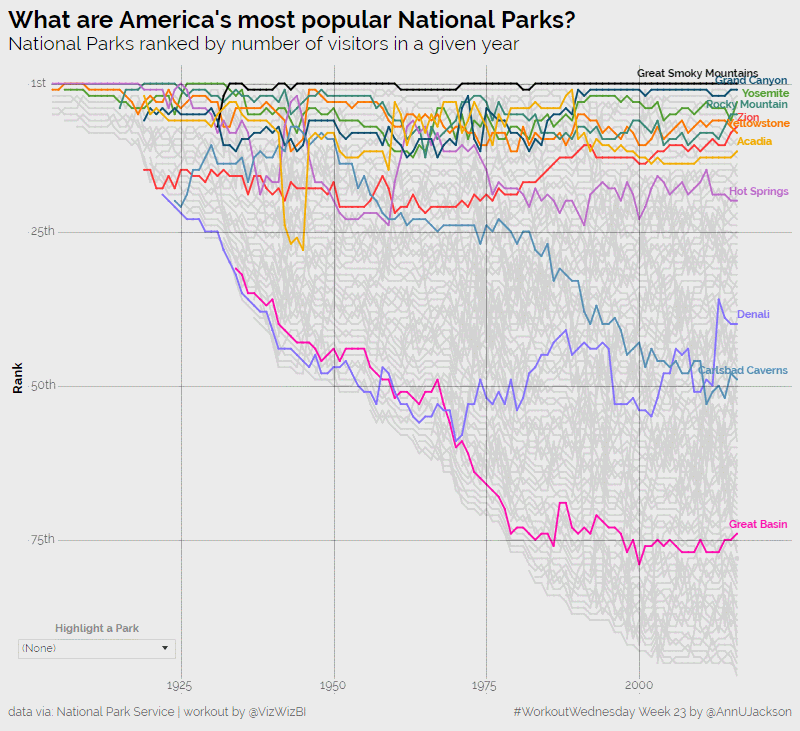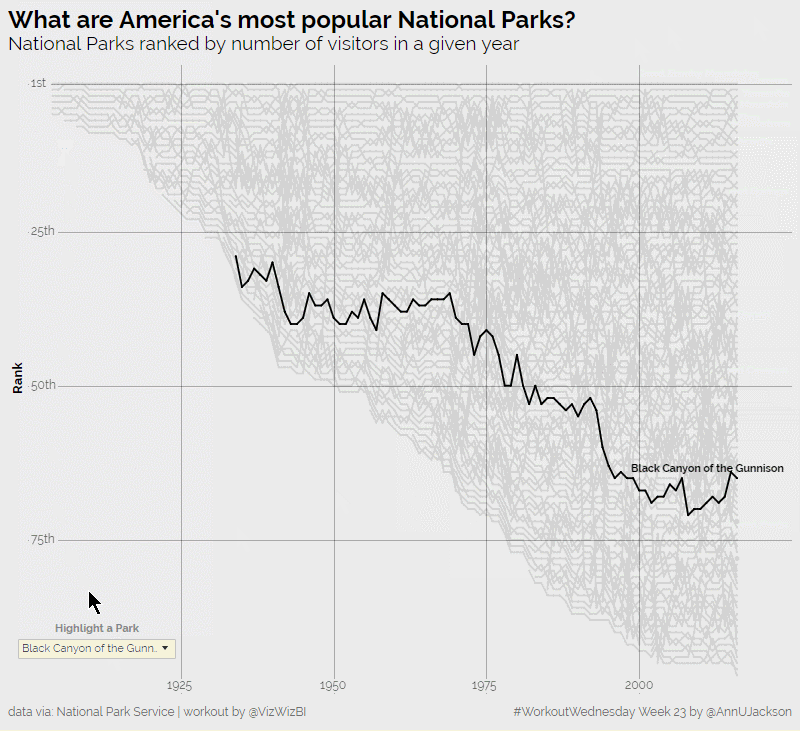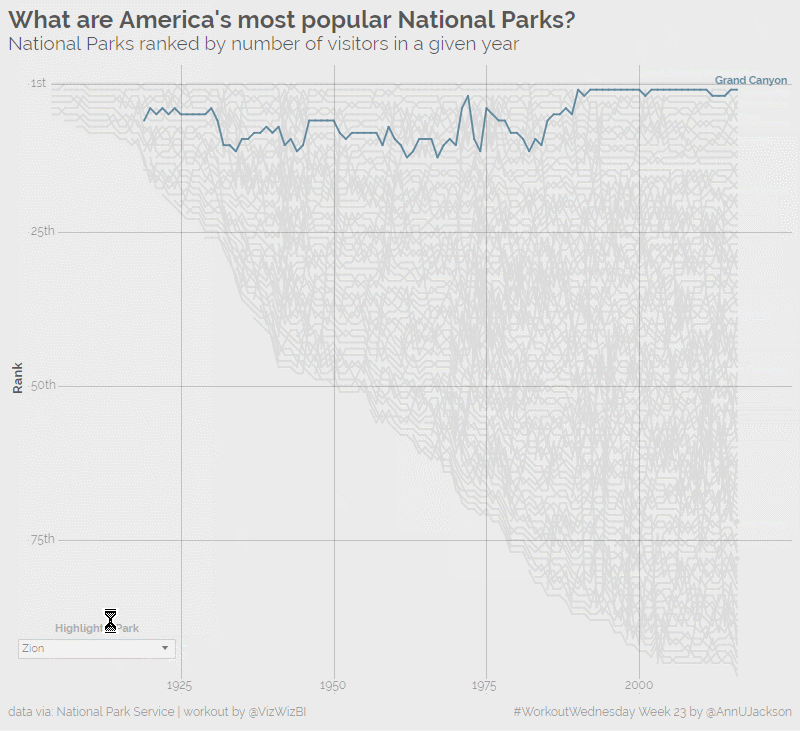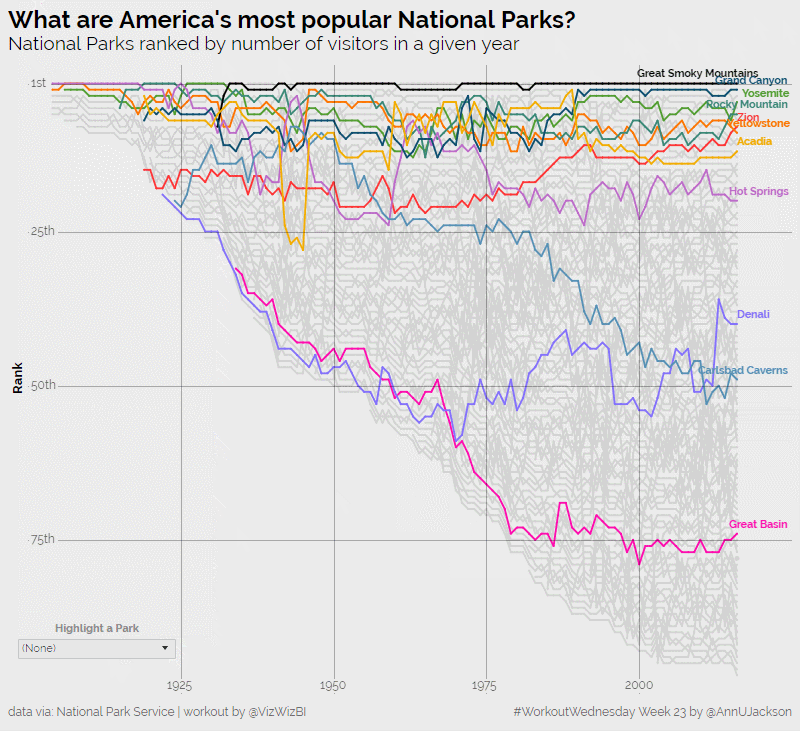
I’m now back in full force from an amazing analytics experience at the Alteryx Inspire conference in Las Vegas. The week was packed with learning, inspiration, and community – things …
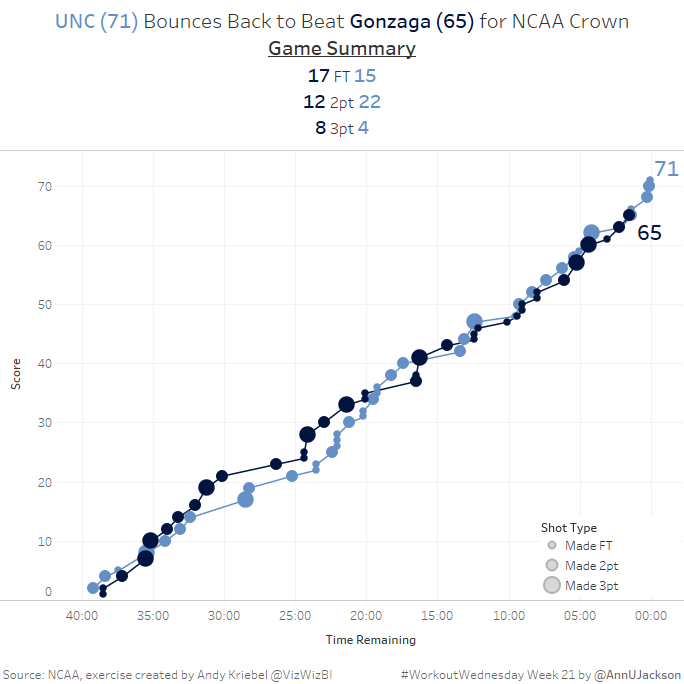
This week’s Workout Wednesday had us taking NCAA data and developing a single chart that showed the cumulative progression of a basketball game. More specifically a line chart where the …

This has been an amazing week for me. On the personal side of things my ship is sailing in the right direction. It’s amazing what the new year can do …
Another great community activity is Workout Wednesday hosted by Andy Kriebel and Emma Whyte. According to Andy it’s “designed to test your knoweldge of Tableau and help you kick on …