#WorkoutWednesday Week 24 – Math Musings
The Workout Wednesday for week 24 is a great way to represent where a result for a particular value falls with respect to a broader collection. I’ve used a spine …
Data Visualization & Analytics Consulting
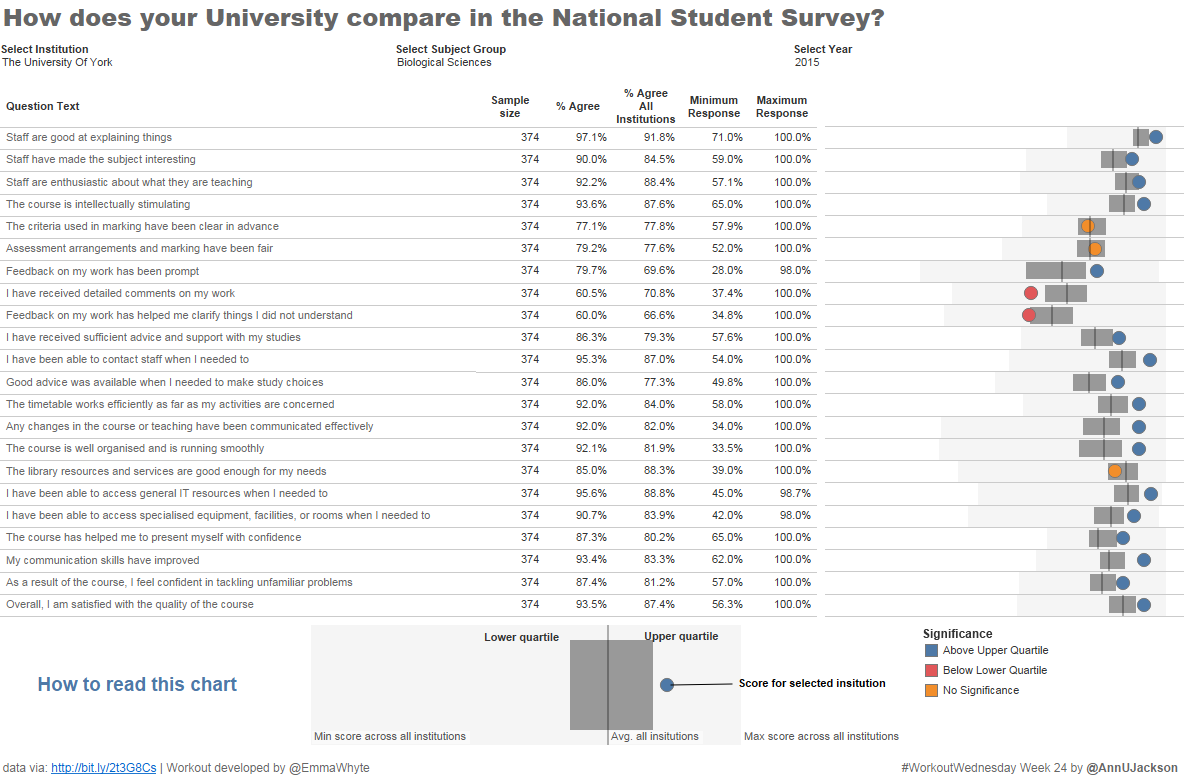
The Workout Wednesday for week 24 is a great way to represent where a result for a particular value falls with respect to a broader collection. I’ve used a spine …