#MakeoverMonday Week 12 – All About March Madness
This week’s Makeover Monday topic was based on an article attempting to provide analysis into why it is harder for people to correctly pick their March Madness brackets. The original …
Data Visualization & Analytics Consulting
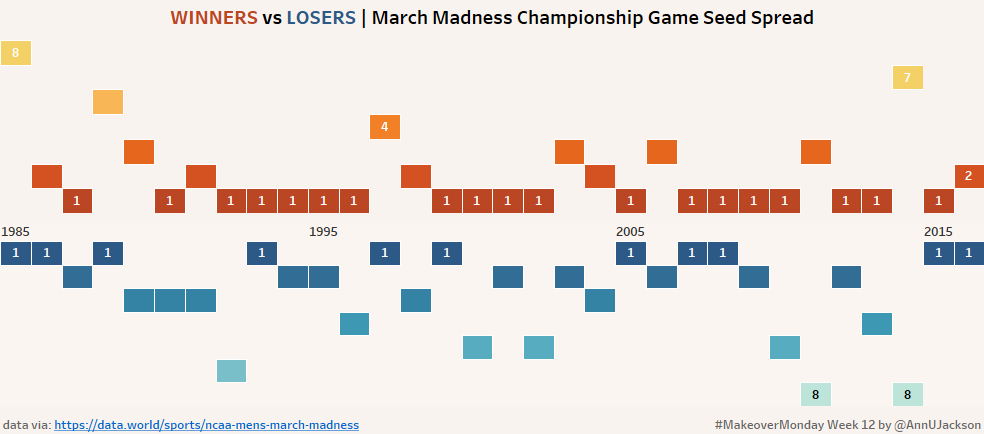
This week’s Makeover Monday topic was based on an article attempting to provide analysis into why it is harder for people to correctly pick their March Madness brackets. The original …
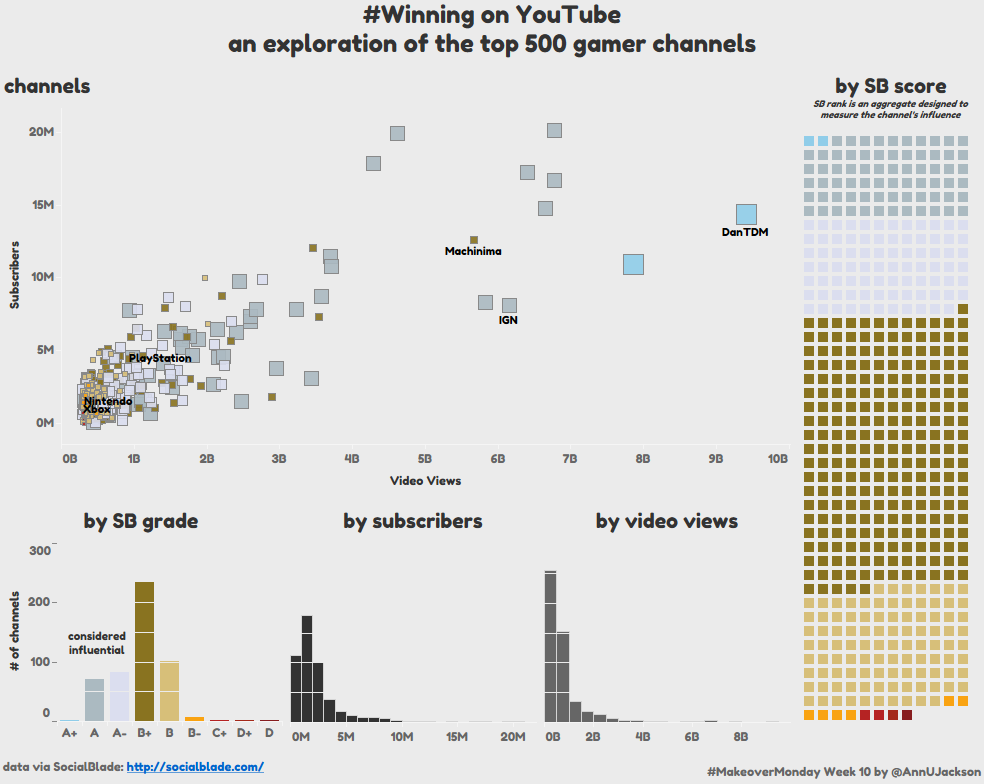
We’re officially 10 weeks into Makeover Monday, which is a phenomenal achievement. This means that I’ve actively participated in recreating 10 different visualizations with data varying from tourism, to Trump, …
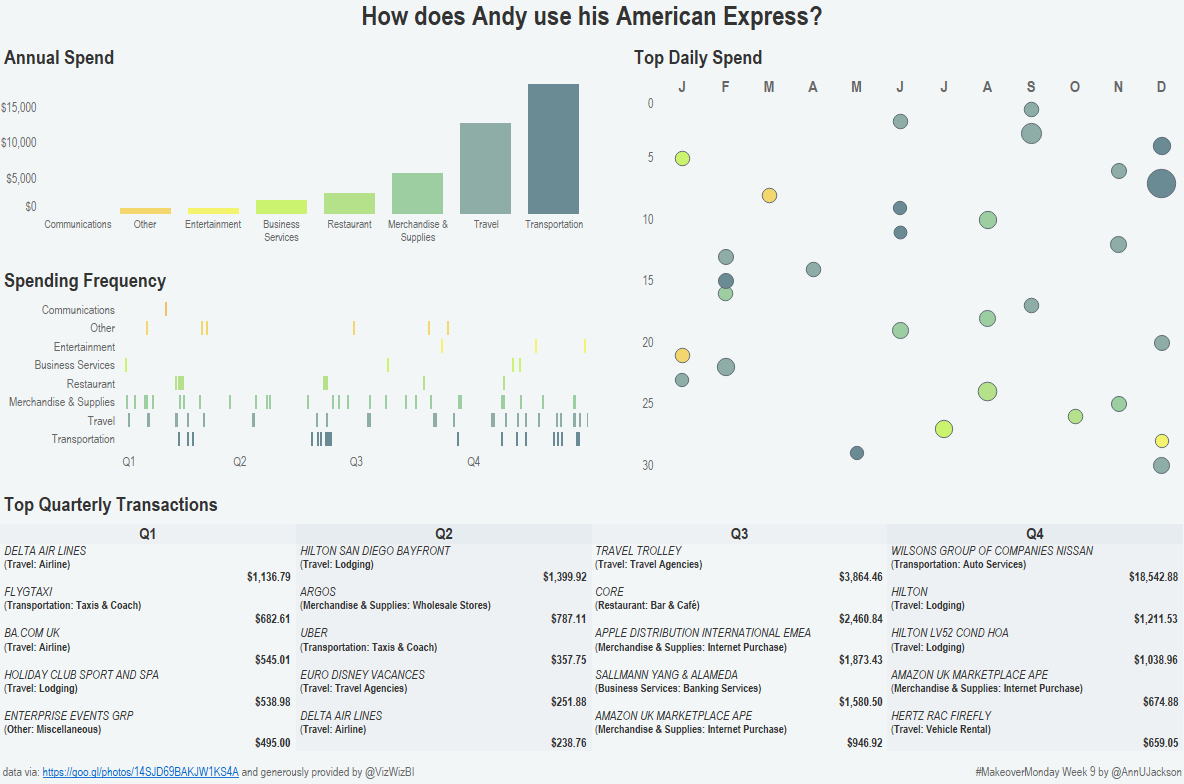
So I started my dream job at the beginning of February. This means I’ve been spending the month adjusting and tweaking my personal schedule and working on bringing back good …
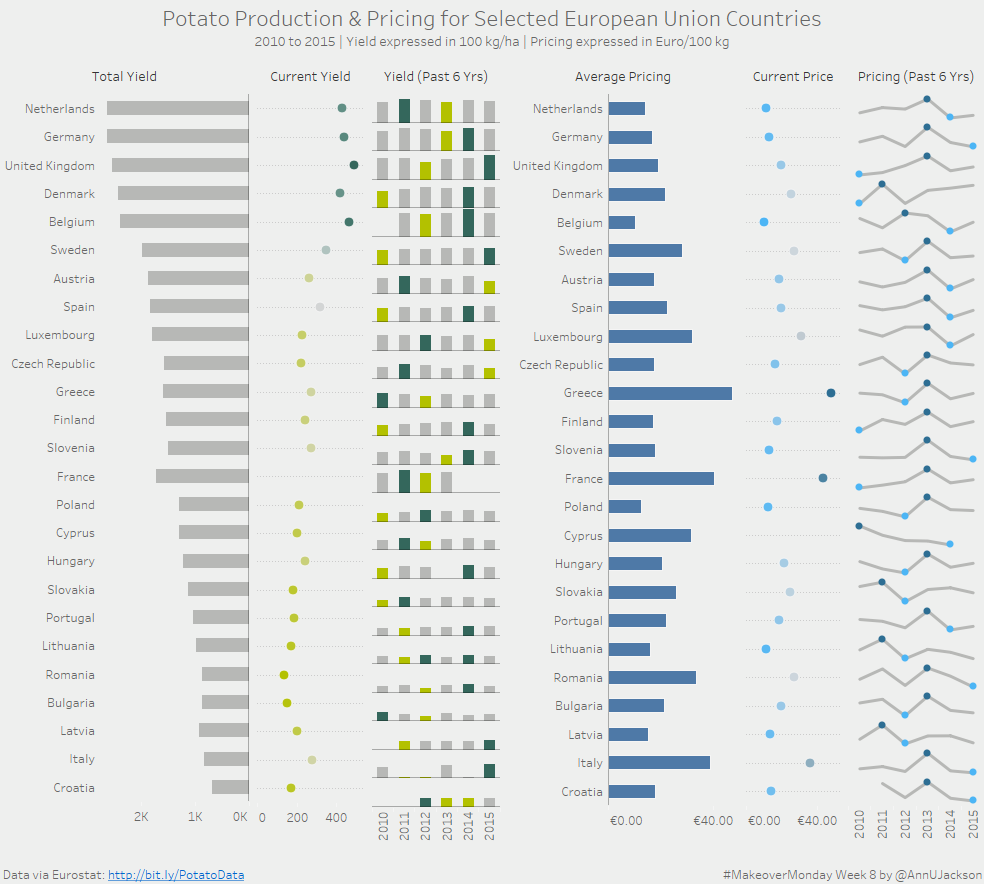
I’ll say this first – I don’t eat potatoes. Although potatoes are super tasty, I refuse to have them as part of my diet. So I was less than thrilled …
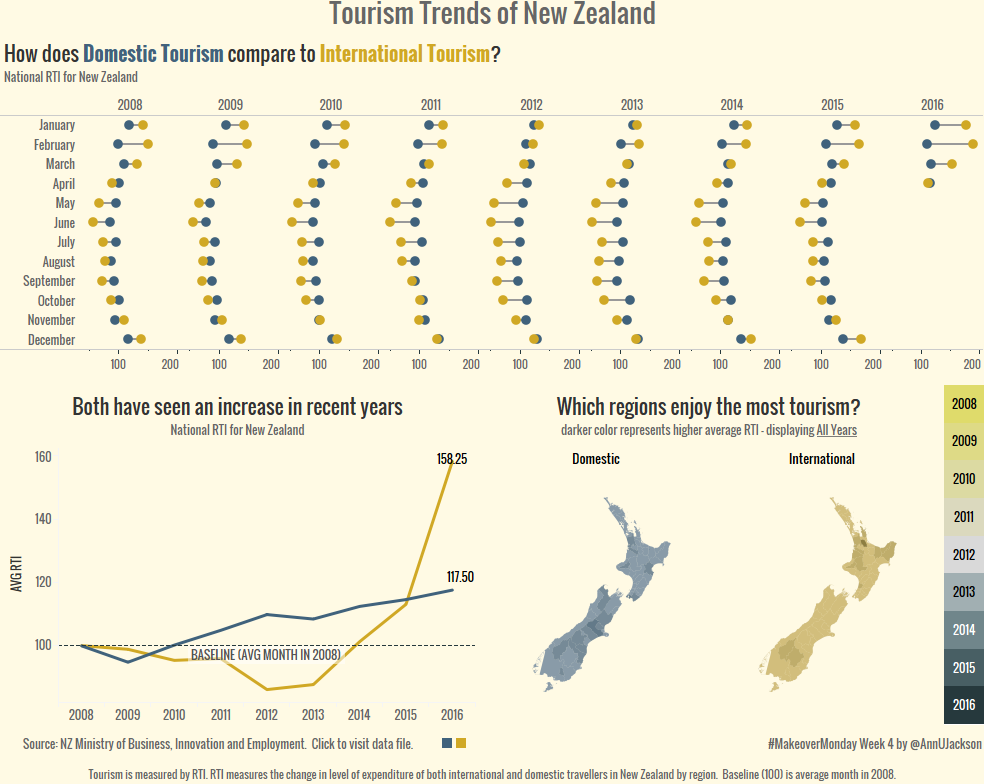
This week’s Makeover was addressing Domestic and International tourism trend in New Zealand. No commentary provided with the data set, the original was just 2 charts left to the user …

**Update (1/20/17) : The original data set had a date formatting snafu resulting in 1307 tweets at the 12:00-12:59 PM (UTC time) hour to be displayed as 00:00-00:59 (aka 12 …

It’s time for Makeover Monday – Week 2. This week’s data set was the quarterly sales (by units) of Apple iPhones for the past 10ish years. The original article accompanying …
It’s officially 2017 – the start of a new year. As such, this is a great time for anyone in the Tableau universe to make a fresh commitment to participate …
And it’s time – my first ever Makeover Monday. I’ll admit, I’ve attempted to catch up in the past, but always lost steam. I think the first data set might …