Aiming for data-driven? Don’t forget the people.
I’ve been in this situation too much recently: I’m having a conversation with someone about the state of analytics and there’s a sudden turn to product feature comparison. What follows …
Data Visualization & Analytics Consulting

I’ve been in this situation too much recently: I’m having a conversation with someone about the state of analytics and there’s a sudden turn to product feature comparison. What follows …
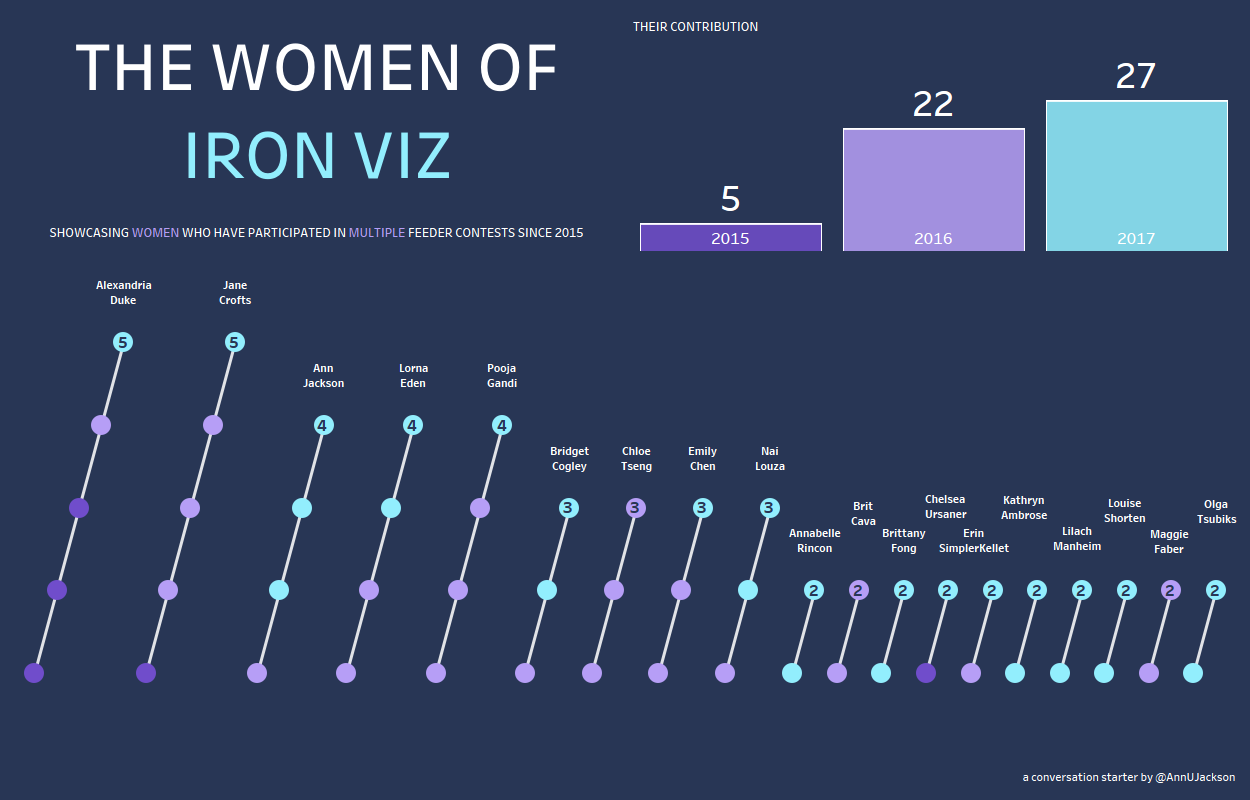
It’s now 5 days removed from the Tableau Conference (#data17) and the topic of women in data visualization and the particularly pointed topic of women competing in Tableau’s #IronViz competition …

Lately I’ve spent a lot of time pondering my role in the world of data. There’s this common phrase that we as data visualization and data analytics (BI) professionals hear …

Have you ever found yourself in a situation where you were looking for opportunities to get more strategic, focus on communication skills, improve your ability to collaborate, or just stretch …
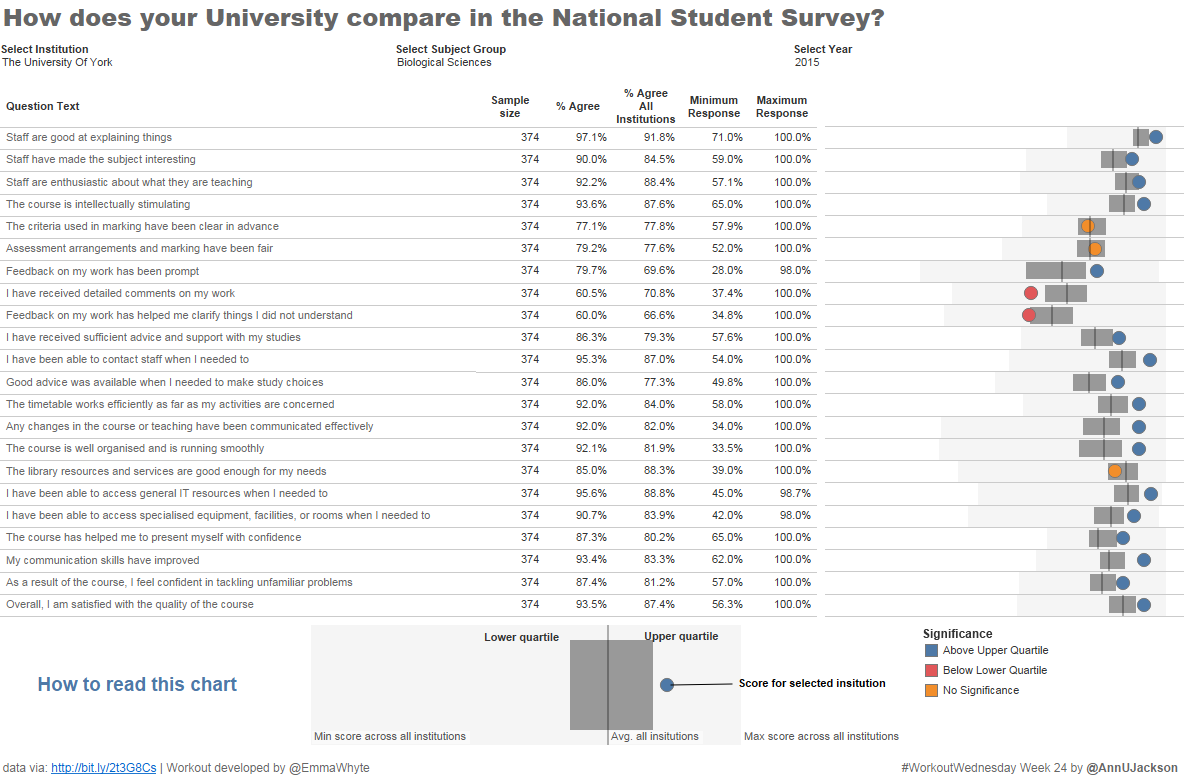
The Workout Wednesday for week 24 is a great way to represent where a result for a particular value falls with respect to a broader collection. I’ve used a spine …
Time for another recount of the content I’ve been consuming. I missed my March post, so I figured it would be fine to do a combined effort. First up: The …
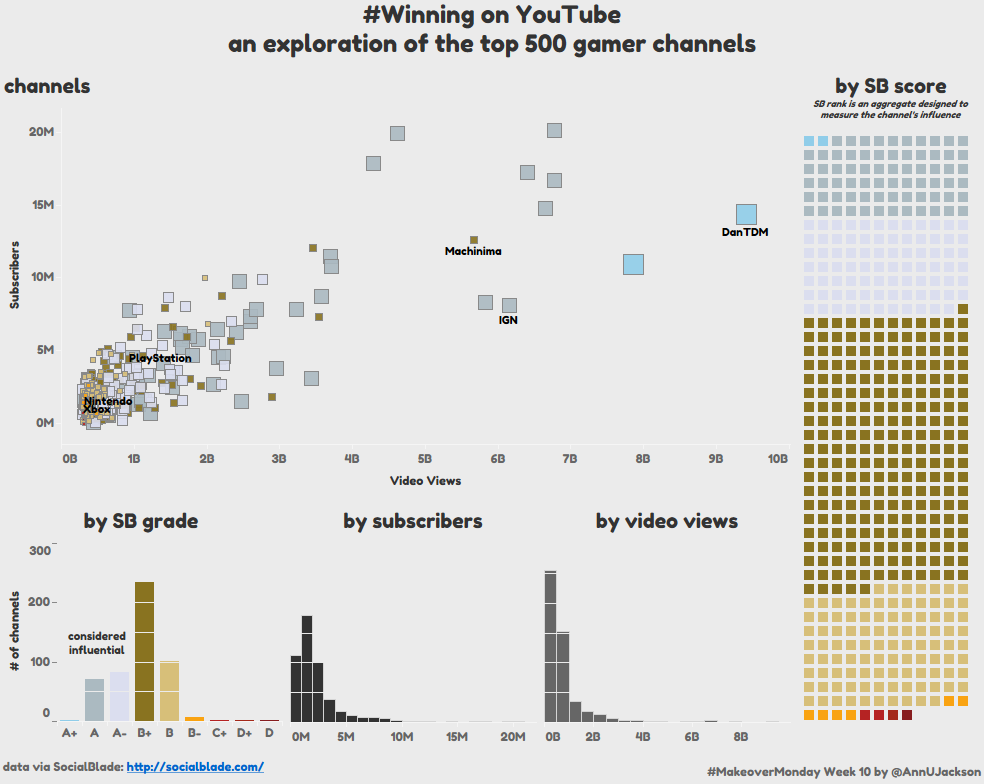
We’re officially 10 weeks into Makeover Monday, which is a phenomenal achievement. This means that I’ve actively participated in recreating 10 different visualizations with data varying from tourism, to Trump, …

Today I decided to take a bit of a detour while working on a potential project for #VizForSocialGood. I was focused on a data set provided by UNICEF that showed …
I recently read this article that really ignited a lot of thoughts that often swirl around in my mind. If you were to ask me what my drive is, it’s …