Dear Data 2019 – Week 6, Physical Contact
Week 6 postcards of the data project Sarah Bartlett and I are working on are here and I couldn’t be more excited. The theme of week 6 was physical contact. …
Data Visualization & Analytics Consulting

Week 6 postcards of the data project Sarah Bartlett and I are working on are here and I couldn’t be more excited. The theme of week 6 was physical contact. …

Week 4 of the data postcard project Sarah Bartlett and I are working on this year is here. We still have yet to reach consistent timing for postcard arrival. Sarah …
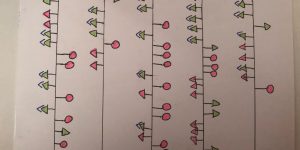
Week 3 postcards for the data project Sarah Bartlett and I are working on this year have finally reached their destinations. I think we both felt that the mail was …
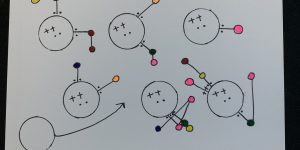
It’s time for week two of the data postcard project Sarah Bartlett and I are working on this year. During this week our focus was spent on transportation, essentially how …
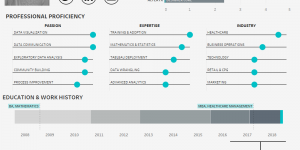
In the age of the connected professional world it’s important to distinguish and differentiate yourself. When it comes to the visual analytics space, a great way to do that is …

I’ve been in this situation too much recently: I’m having a conversation with someone about the state of analytics and there’s a sudden turn to product feature comparison. What follows …

Recently I had the opportunity to finish my first Tableau Foundation Service Corp consult. Something that’s been 2 years in the making. Since my early exposure to the Tableau community …
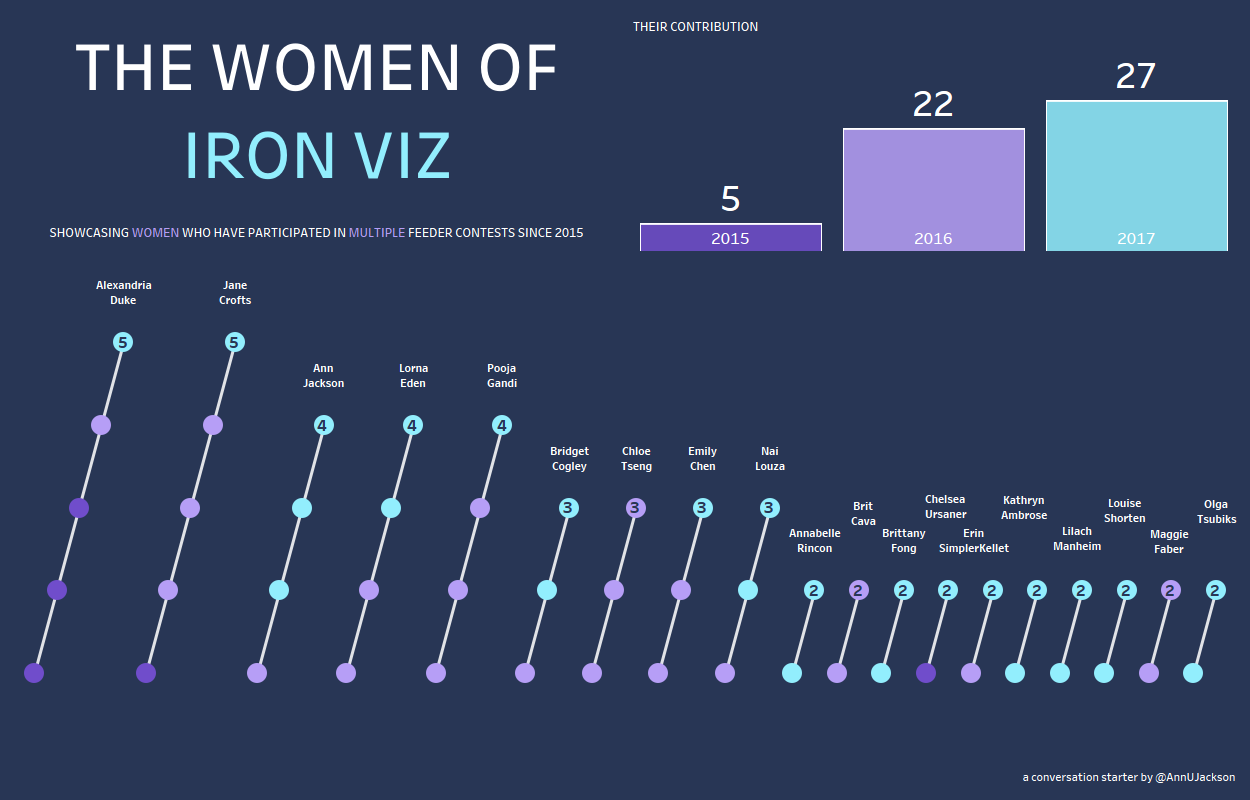
It’s now 5 days removed from the Tableau Conference (#data17) and the topic of women in data visualization and the particularly pointed topic of women competing in Tableau’s #IronViz competition …

Lately I’ve spent a lot of time pondering my role in the world of data. There’s this common phrase that we as data visualization and data analytics (BI) professionals hear …

Have you ever found yourself in a situation where you were looking for opportunities to get more strategic, focus on communication skills, improve your ability to collaborate, or just stretch …