The Shape of Shakespeare’s Sonnets | #IronViz Books & Literature
Jump directly to the viz If it’s springtime that can only mean that it’s time to begin the feeder rounds for Tableau’s Iron Viz contest. The kick-off global theme for …
Data Visualization & Analytics Consulting

Jump directly to the viz If it’s springtime that can only mean that it’s time to begin the feeder rounds for Tableau’s Iron Viz contest. The kick-off global theme for …

Recently I had the opportunity to finish my first Tableau Foundation Service Corp consult. Something that’s been 2 years in the making. Since my early exposure to the Tableau community …
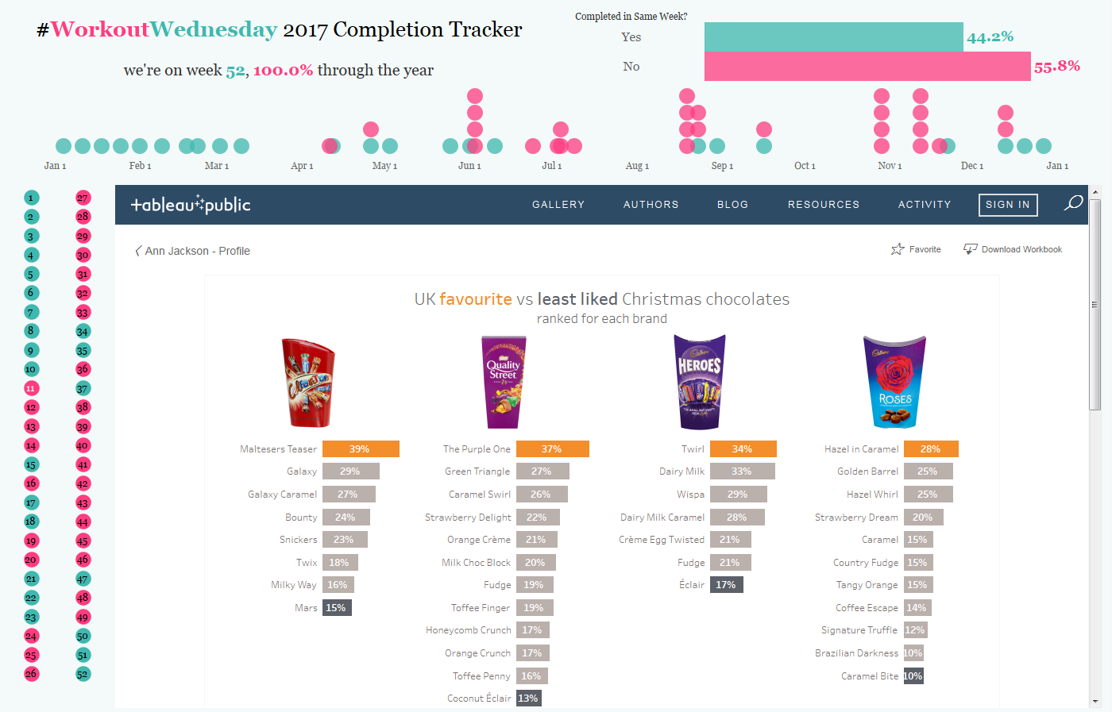
Back in July I wrote the first half of this blog post – it was about the first 27 weeks of #WorkoutWednesday. The important parts to remember (if the read …

Have you ever found yourself in a situation where you were looking for opportunities to get more strategic, focus on communication skills, improve your ability to collaborate, or just stretch …

I’ve long been a huge advocate of certification in technical fields. I think it is a great way to actively communicate and demonstrate the skill level you have in a …
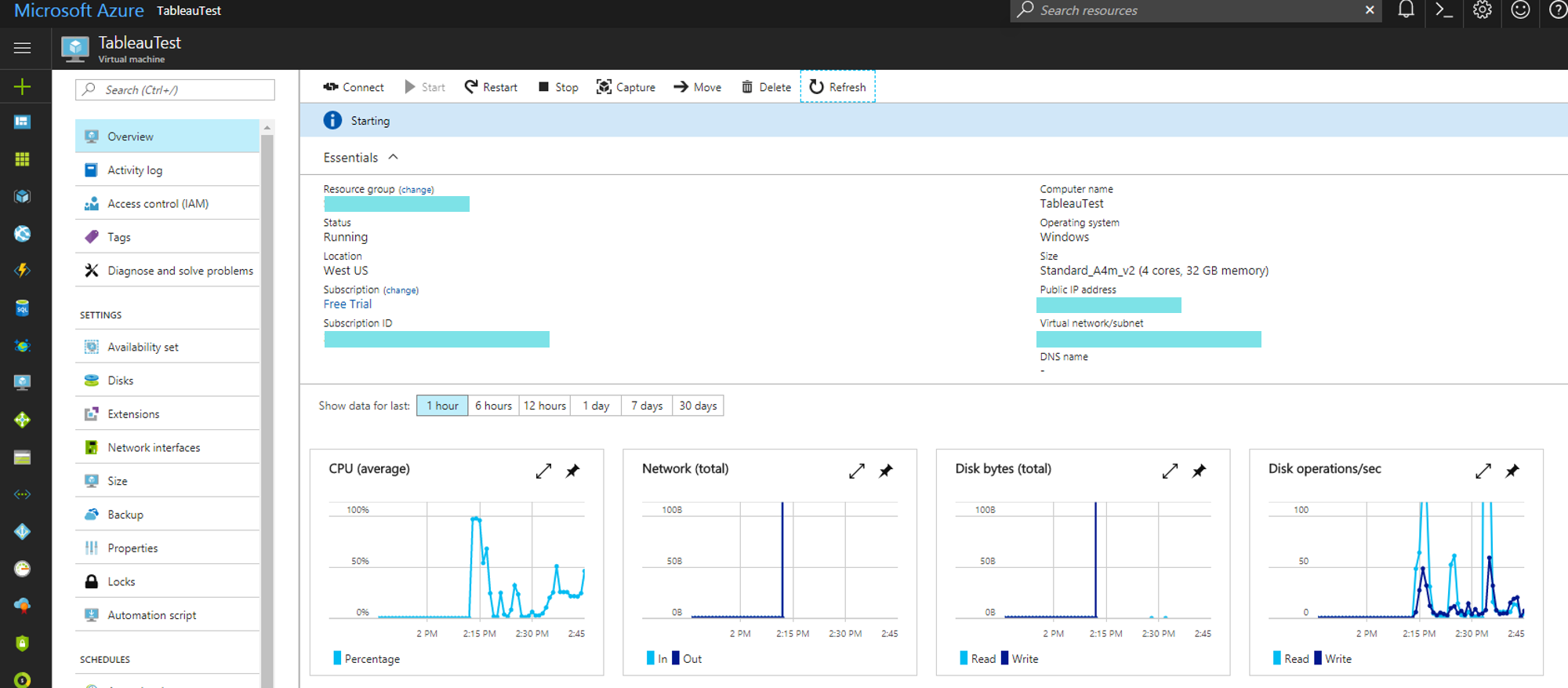
I’m affectionately calling this post Azure + Tableau Server = Flex for two reasons. First – are you a desktop user that has always wanted to extend your skills in …

Another month has passed, so it’s time to recount what I’ve been reading. Admittedly it was kind of a busy month for me, so I decided to mix up some …
It’s time for another edition of book binge – a random category of blog posts devised (and now only on its second iteration) where I walk through the different books …

Today I decided to take a bit of a detour while working on a potential project for #VizForSocialGood. I was focused on a data set provided by UNICEF that showed …
Tableau 10.2 is on the horizon and with it comes several new features – one that is of particular interest to me is their new Python integration. Here’s the Beta …