Who Gets an Olympic Medal | #MakeoverMonday Week 7
At the time of writing the 2018 Winter Olympic Games are in full force, so it seems only natural that the #MakeoverMonday topic for Week 7 of this year is …
Data Visualization & Analytics Consulting
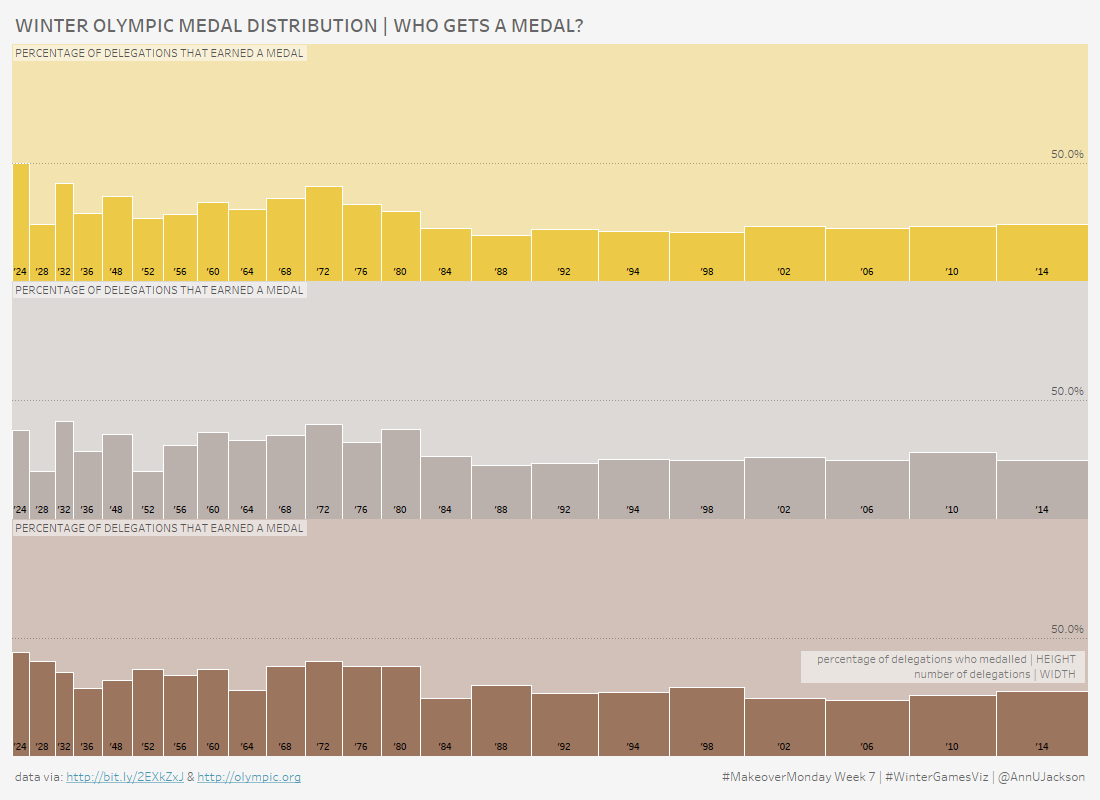
At the time of writing the 2018 Winter Olympic Games are in full force, so it seems only natural that the #MakeoverMonday topic for Week 7 of this year is …

Recently I had the opportunity to finish my first Tableau Foundation Service Corp consult. Something that’s been 2 years in the making. Since my early exposure to the Tableau community …
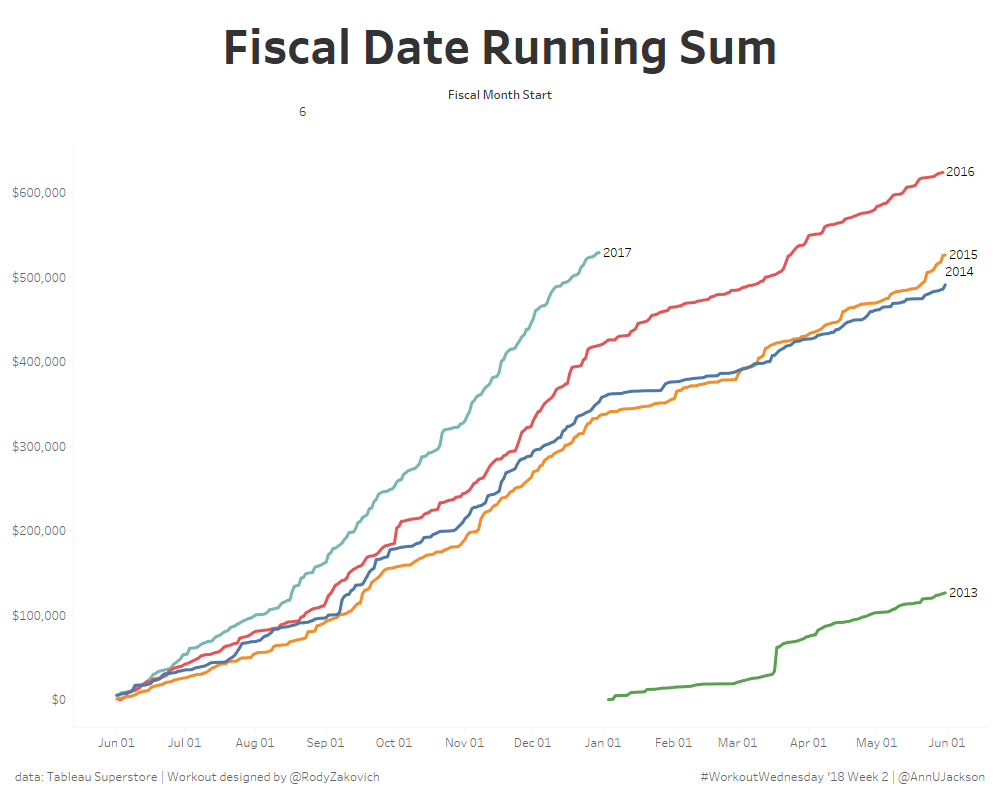
As a big advocate of #WorkoutWednesday I am excited to see that it is continuing on in 2018. I champion the initiative because it offers people a constructive way to …
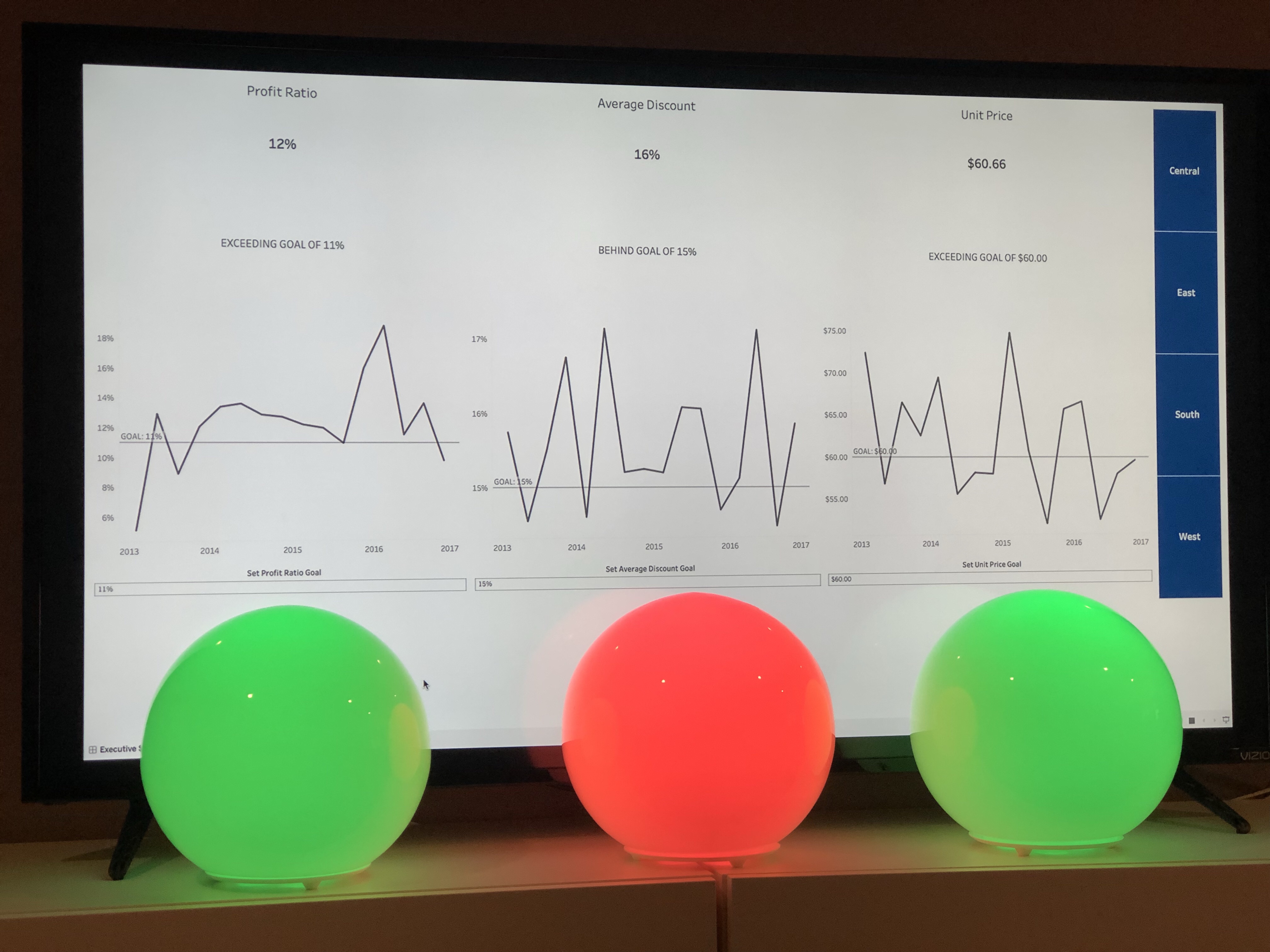
You’ve asked and it’s time to answer. About a week ago I posted a teaser video on Twitter that showed how I integrated my home automation system with a Tableau …
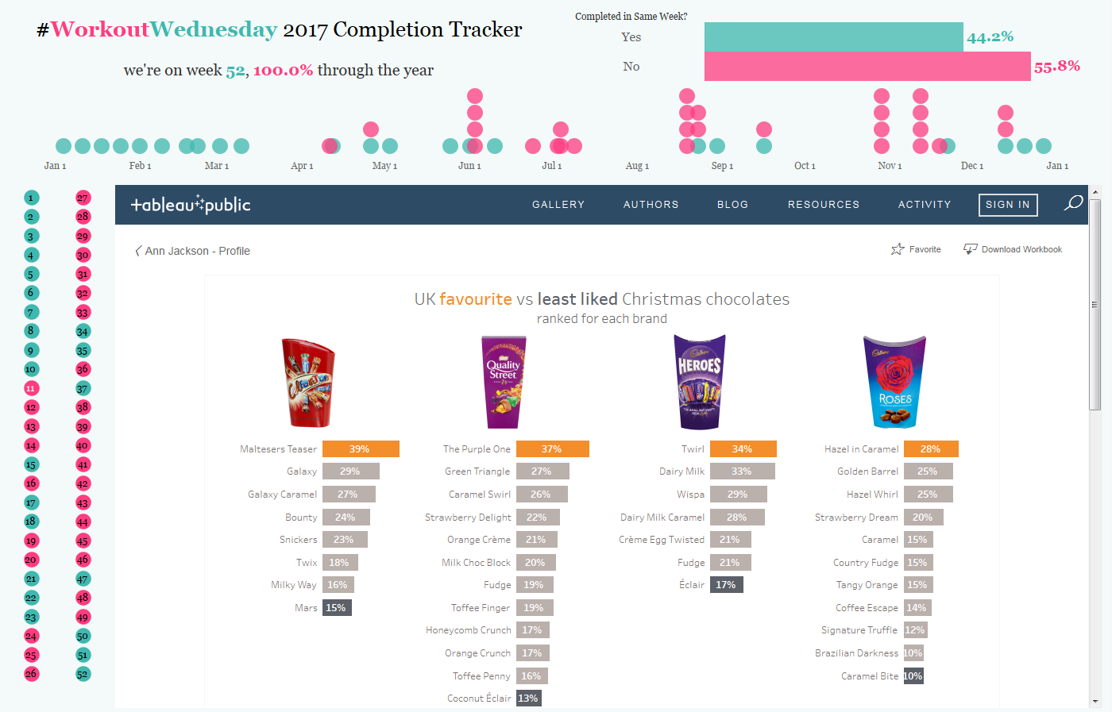
Back in July I wrote the first half of this blog post – it was about the first 27 weeks of #WorkoutWednesday. The important parts to remember (if the read …
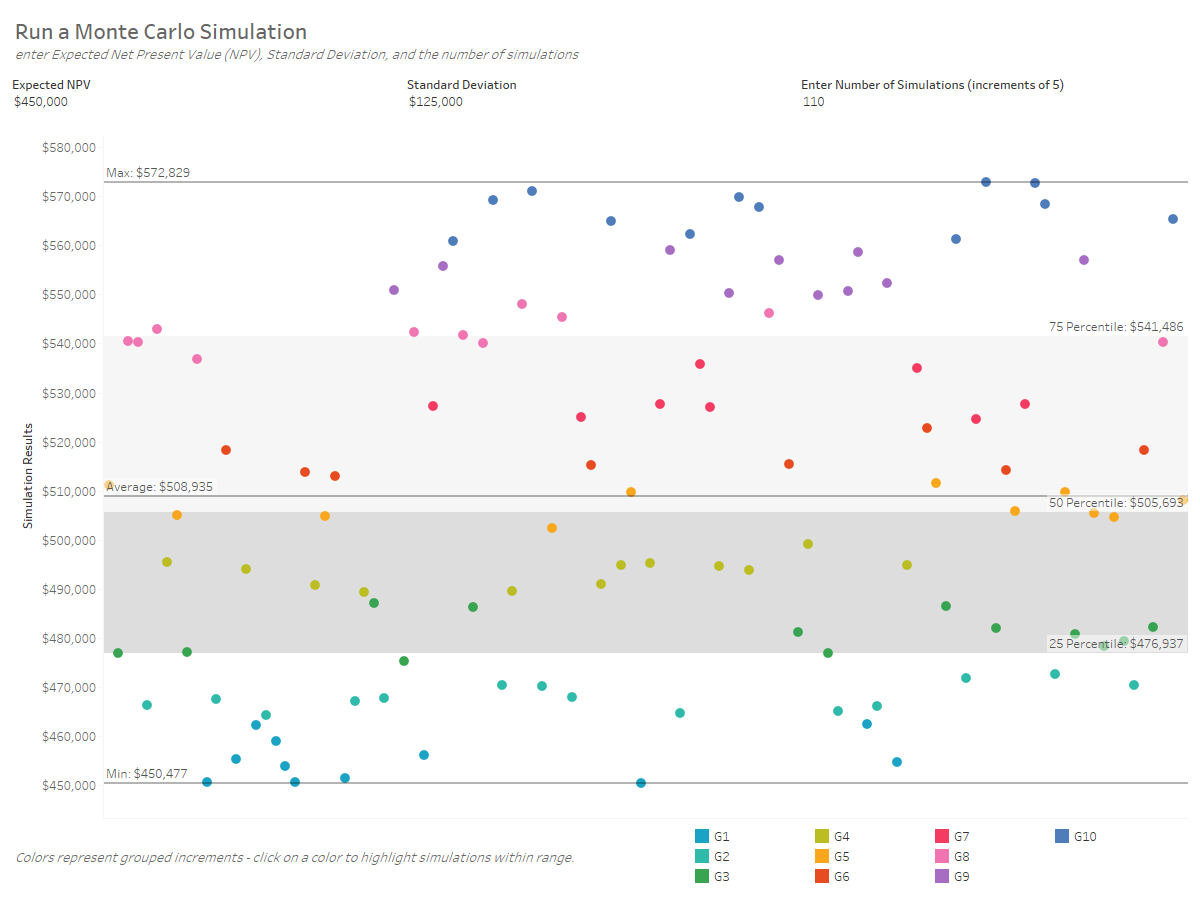
This month I’ve been taking a night class at Galvanize aimed at being an introductory to Python and Data Science. It’s a 4 night/week boot camp with a mix of …
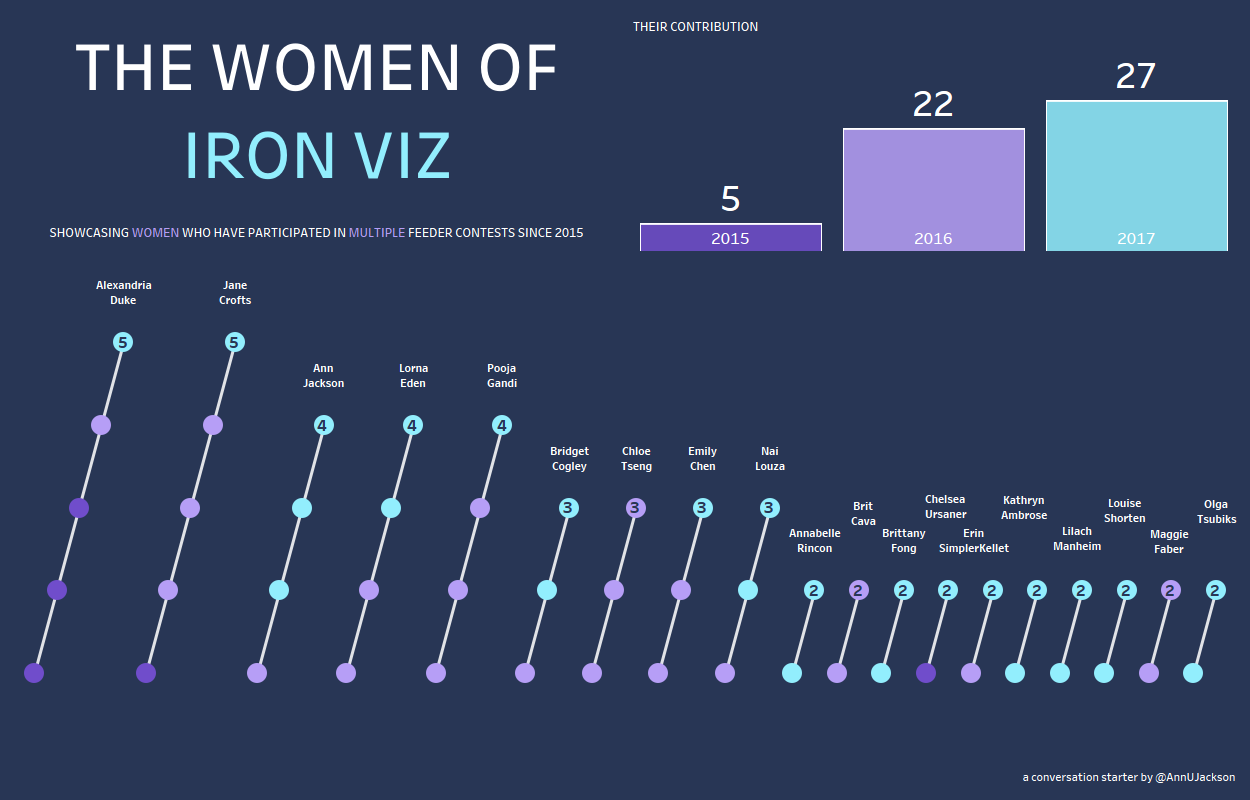
It’s now 5 days removed from the Tableau Conference (#data17) and the topic of women in data visualization and the particularly pointed topic of women competing in Tableau’s #IronViz competition …

Now that Tableau Conference 2017 has come to a close it’s time to reflect back on my favorite and most memorable moments. I’ll preface by saying that I had very …

I’ve long been a huge advocate of certification in technical fields. I think it is a great way to actively communicate and demonstrate the skill level you have in a …
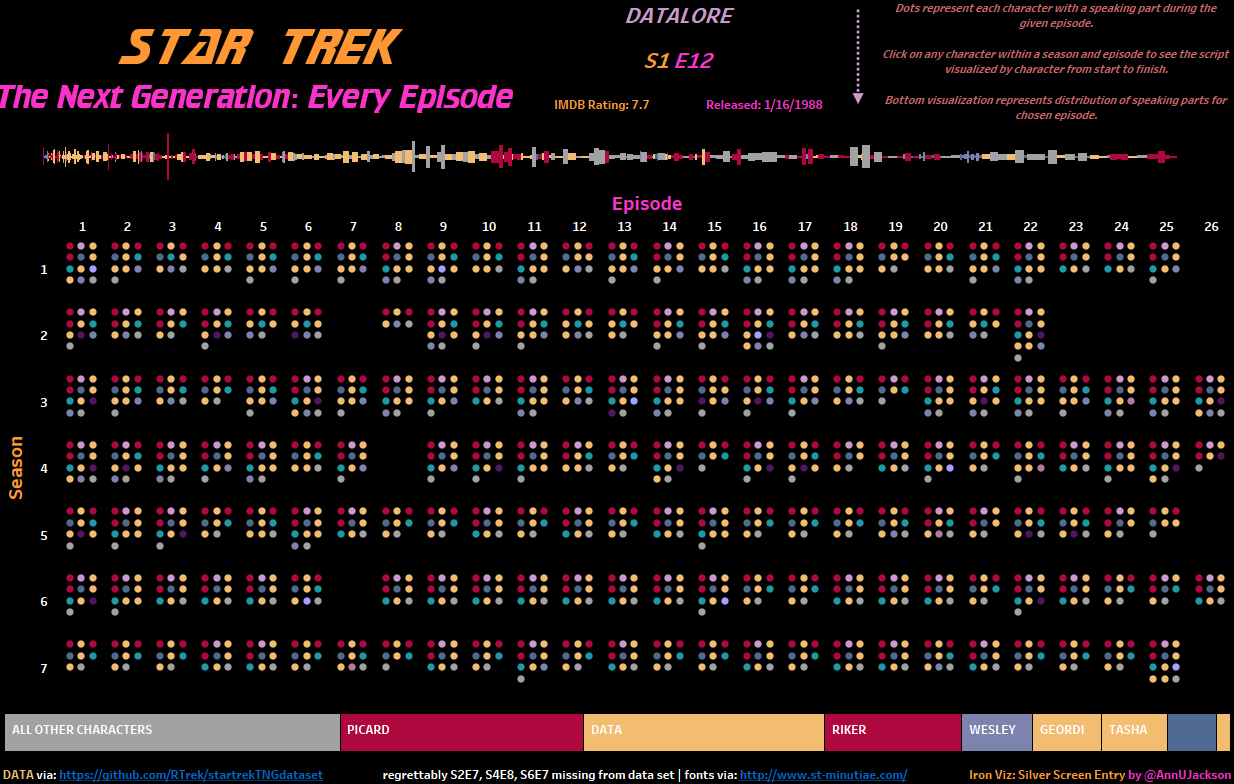
It’s that time again – Iron Viz feeder contest! The third and final round for a chance to battle at conference in a chef coat is upon us. This round …