Dynamic Quantile Map Coloring in Tableau Desktop
Last week at Tableau’s customer conference (TC18) in New Orleans I had the pleasure of speaking in three different sessions, all extremely hands on in Tableau Desktop. Two of the …
Data Visualization & Analytics Consulting
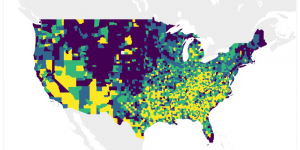
Last week at Tableau’s customer conference (TC18) in New Orleans I had the pleasure of speaking in three different sessions, all extremely hands on in Tableau Desktop. Two of the …
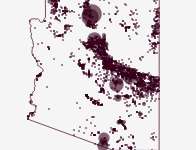
Jump directly to the viz At the time of writing it is 100°F outside my window in Arizona and climbing. It’s also August and we’re right in the middle of …
We all know the value of having a brand, whether it’s your personal brand or your organization’s brand, it’s the differentiator that distinguishes you from others. It’s what makes us …
In the age of the connected professional world it’s important to distinguish and differentiate yourself. When it comes to the visual analytics space, a great way to do that is …

One of my favorite visualizations is the sparkline – I always appreciated how they are described by Edward Tufte “data-intense, design-simple, word-sized graphics.” Meaning the chart gets right to the …

Jump directly to the viz If it’s springtime that can only mean that it’s time to begin the feeder rounds for Tableau’s Iron Viz contest. The kick-off global theme for …

Week 18 of Makeover Monday tackles the issue of the declining bee population in the United States. Data was provided by BeeInformed and the re-visualization is in conjunction with Viz …
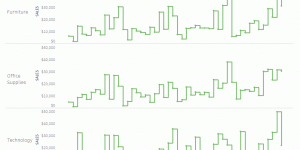
What better way to celebrate the release of step lines and jump lines in Tableau Desktop with a workout aimed at doing them the hard way? Using alternative line charts …
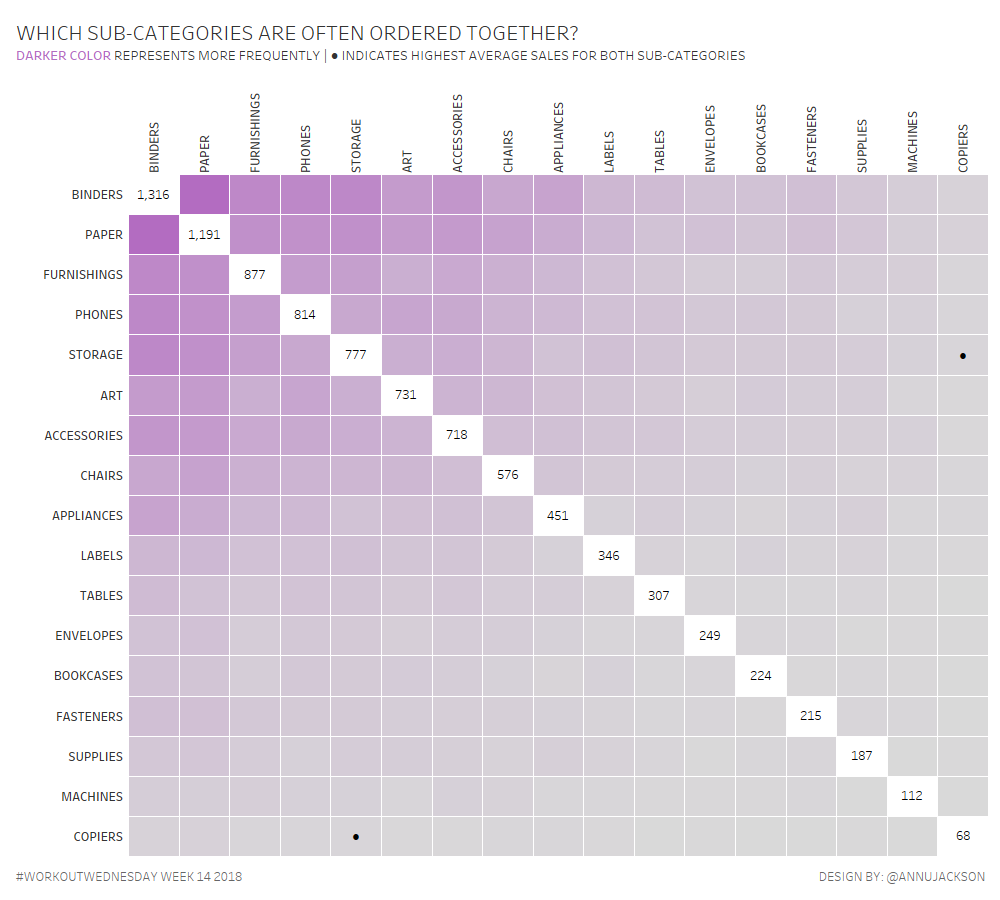
Earlier in the month Luke Stanke asked if I would write a guest post and workout. As someone who completed all 52 workouts in 2017, the answer was obviously YES! …
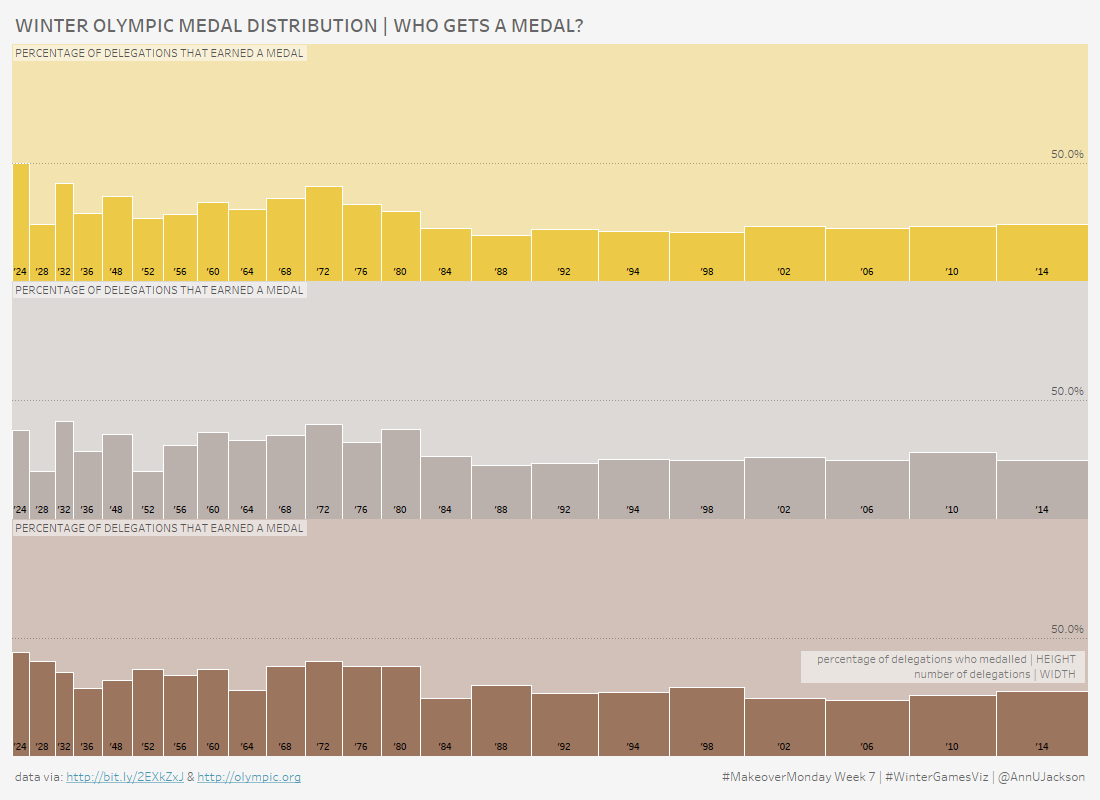
At the time of writing the 2018 Winter Olympic Games are in full force, so it seems only natural that the #MakeoverMonday topic for Week 7 of this year is …