#IronViz – Let’s Go on a Pokémon Safari!
It’s that time again – Iron Viz! The second round of Iron Viz entered my world via an email with a very enticing “Iron Viz goes on Safari!” theme. My …
Data Visualization & Analytics Consulting

It’s that time again – Iron Viz! The second round of Iron Viz entered my world via an email with a very enticing “Iron Viz goes on Safari!” theme. My …
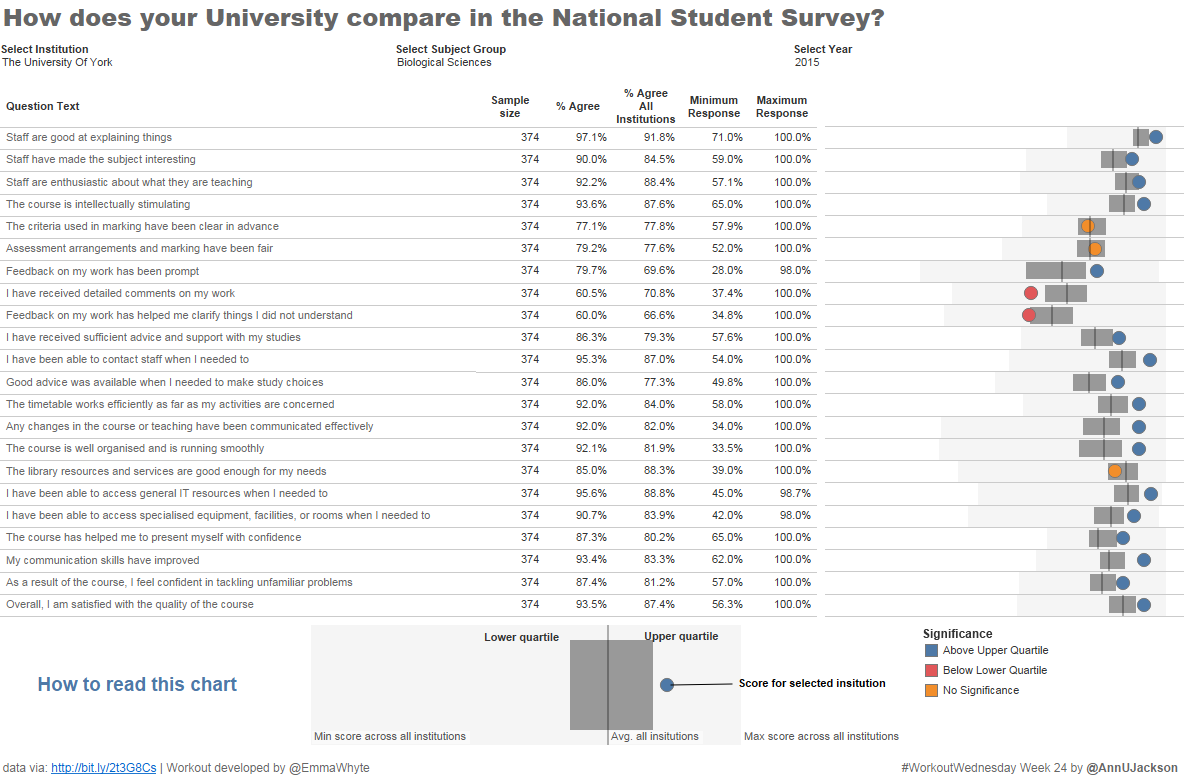
The Workout Wednesday for week 24 is a great way to represent where a result for a particular value falls with respect to a broader collection. I’ve used a spine …

We had another giant data set this week – 202 million records of EPA Ozone readings across the United States. The giant data set is generously hosted by Exasol. I …
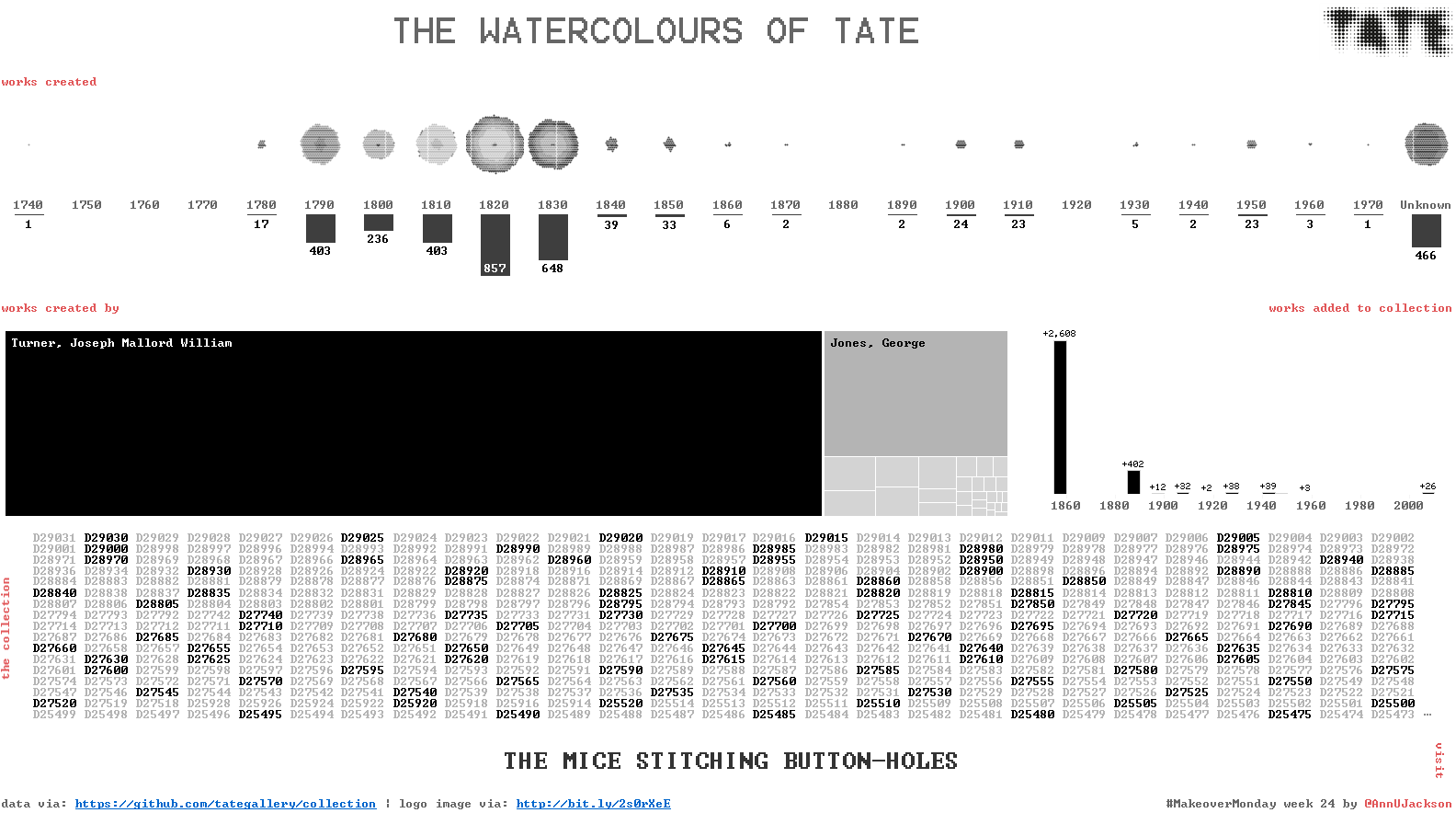
First – I apologize. I did a lot of web editing this week that has led to a series of system fails. The first was spelling the hashtag wrong. Next …
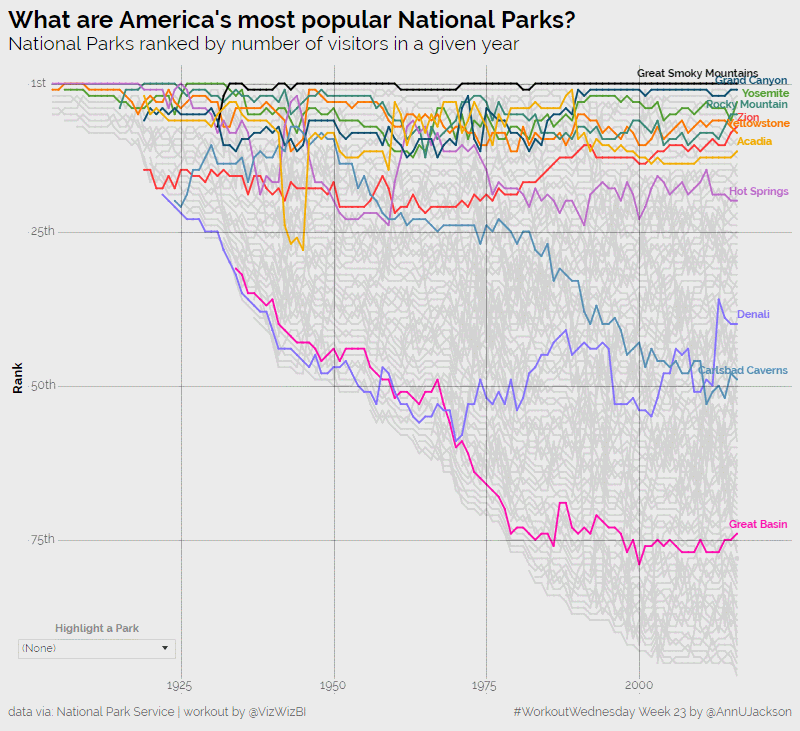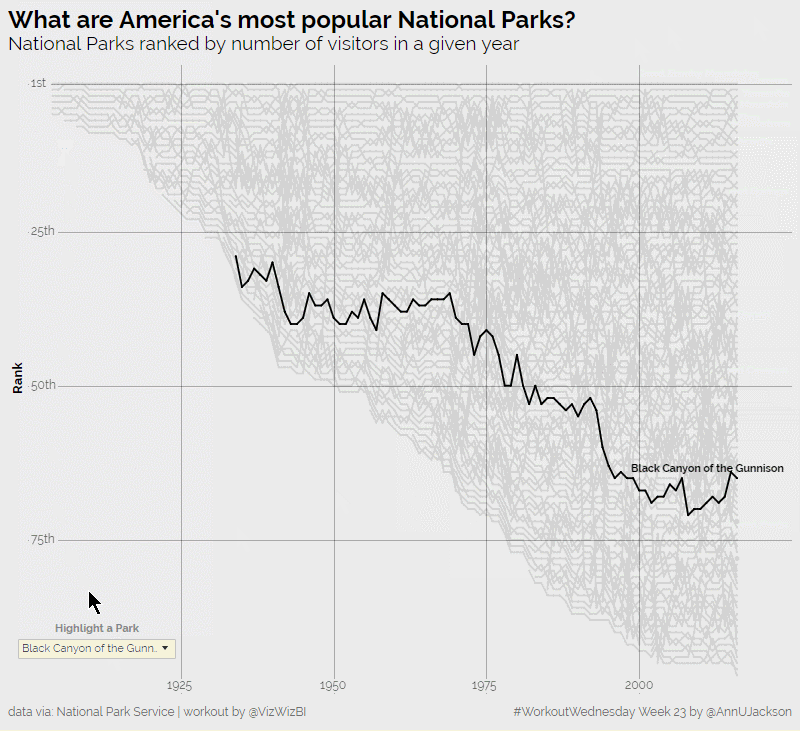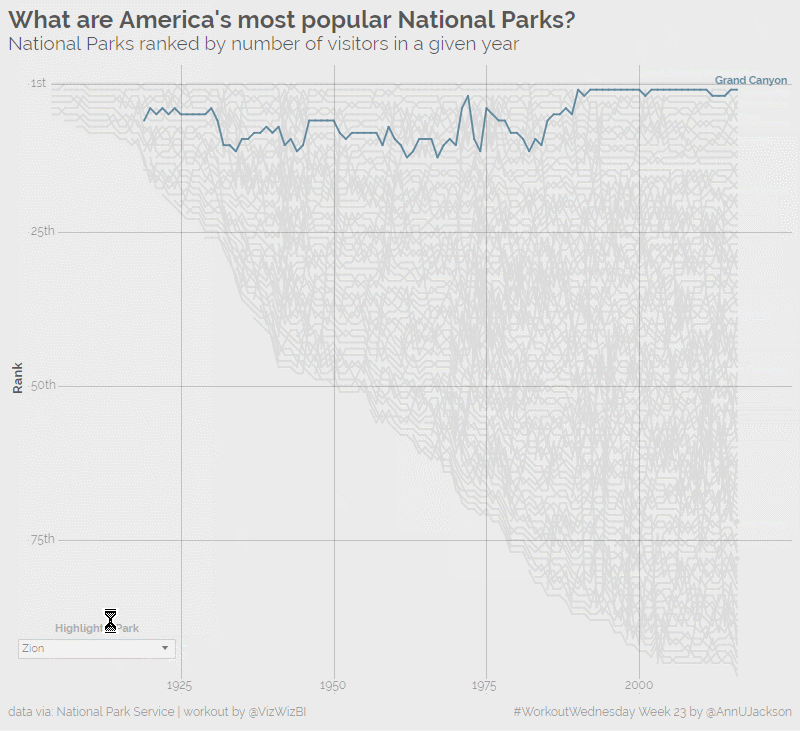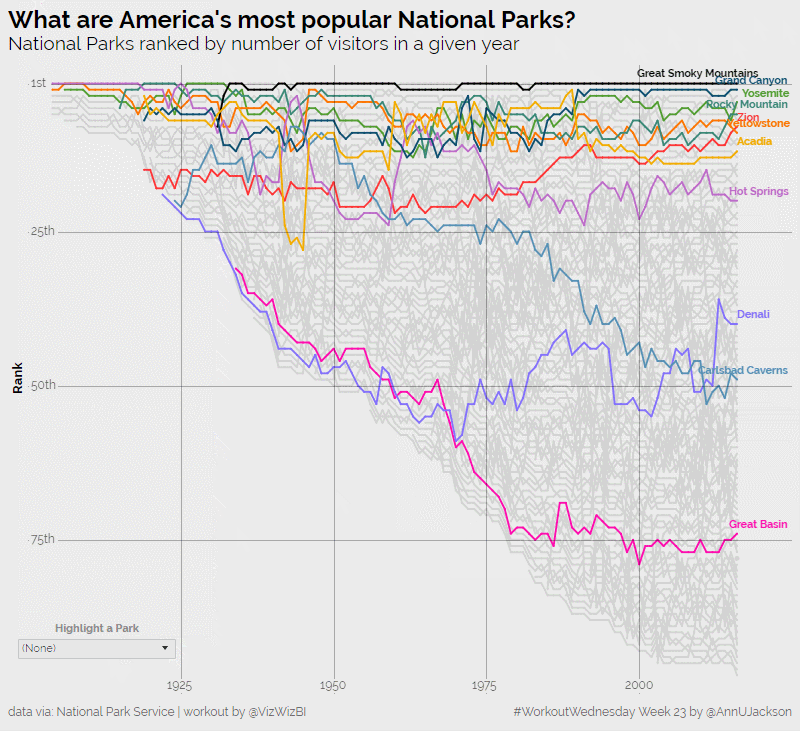
I’m now back in full force from an amazing analytics experience at the Alteryx Inspire conference in Las Vegas. The week was packed with learning, inspiration, and community – things …

When I went to the Tableau Conference last year, I felt it was important to spend some time documenting my experience. Anytime I go to a conference related to my …