#MakeoverMonday Week 12 – All About March Madness
This week’s Makeover Monday topic was based on an article attempting to provide analysis into why it is harder for people to correctly pick their March Madness brackets. The original …
Data Visualization & Analytics Consulting
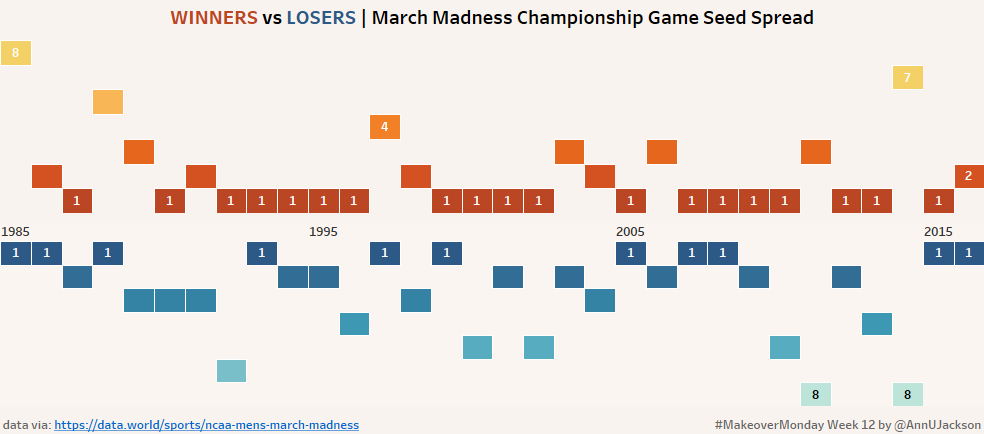
This week’s Makeover Monday topic was based on an article attempting to provide analysis into why it is harder for people to correctly pick their March Madness brackets. The original …

Another month has passed, so it’s time to recount what I’ve been reading. Admittedly it was kind of a busy month for me, so I decided to mix up some …
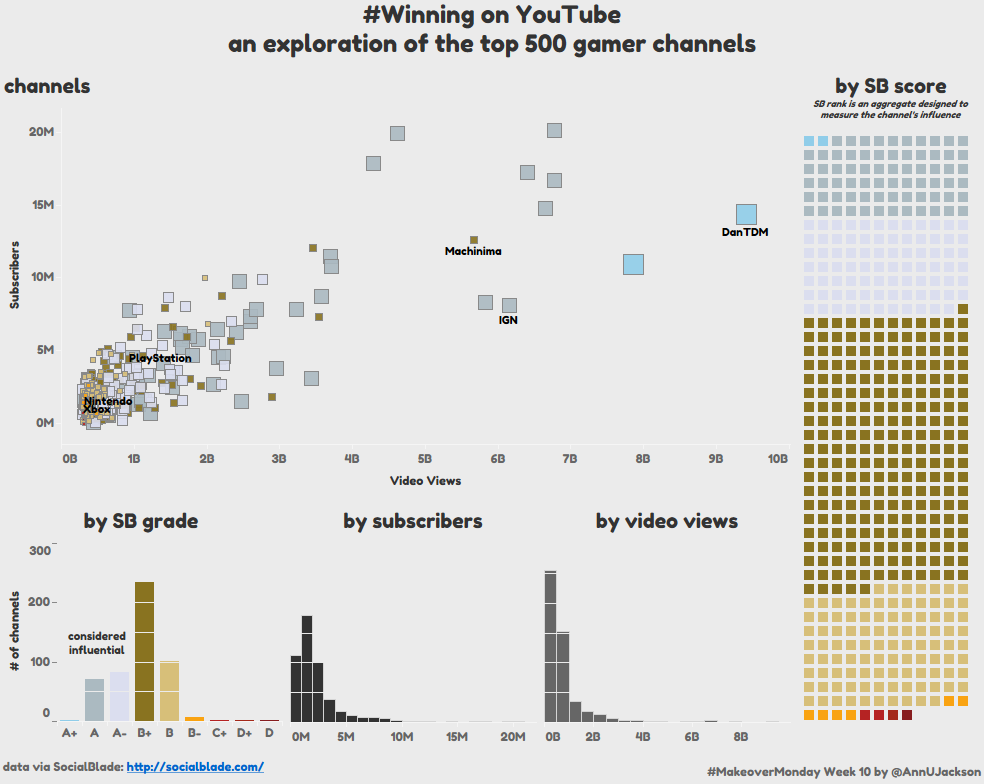
We’re officially 10 weeks into Makeover Monday, which is a phenomenal achievement. This means that I’ve actively participated in recreating 10 different visualizations with data varying from tourism, to Trump, …
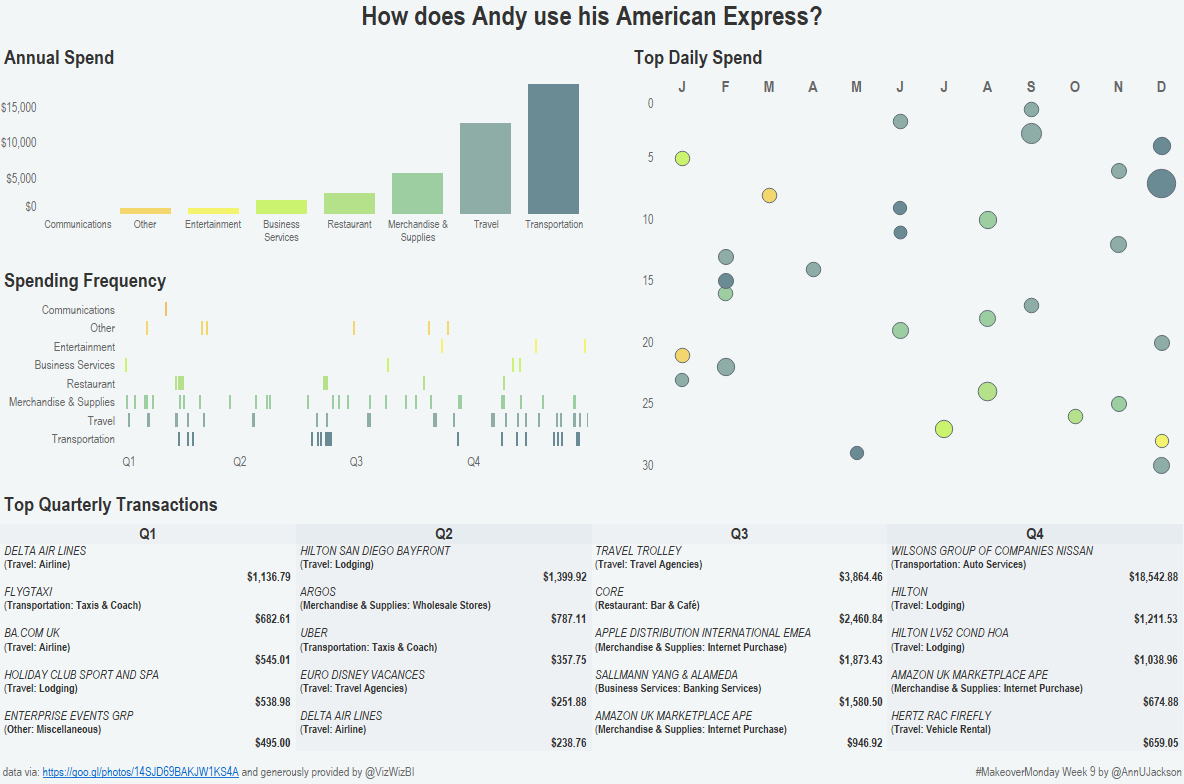
So I started my dream job at the beginning of February. This means I’ve been spending the month adjusting and tweaking my personal schedule and working on bringing back good …